Top 7 B2B Data Challenges You Need to Know About [+Solution]
Discover top B2B data challenges and learn how you can fix inaccurate, outdated, and siloed data to improve pipeline and sales performance.
Published
Written by
Chris P.
Reviewed by
Nithish A.
Read time
7
minutes

B2B data challenges are operational problems that arise when the contact, account, and firmographic data sales and marketing teams rely on is inaccurate, outdated, siloed, or non-compliant. The consequences show up directly in the pipeline. According to Salesforce, sales teams spend just 30% of their time actually selling, with the rest lost to admin work, bad data, and manual research.
If you’re trying to understand what’s causing pipeline gaps, missed quotas, or wasted campaign spend, the answer is usually one of seven data problems. This guide breaks each one down and explains how teams can fix it.
Key Takeaways
Data decay is the root challenge that makes every other problem on this list worse: a database that starts clean loses roughly one in four records to job changes, restructures, and updates within 12 months.
Inaccurate and incomplete data, siloed systems, and inconsistent formatting are distinct problems that each requires a different fix, and solving one does not automatically fix the others.
Compliance is not just a legal concern: GDPR applies to any company targeting EU residents regardless of where it is based.
The most effective fix across all seven challenges is moving from static, periodically refreshed data to a live data layer that reflects what is actually happening at a company right now.
1. Data Decay
Data decay is the gradual degradation of the accuracy of B2B contact data as people change jobs, companies restructure, and contact details become obsolete. Research has shown that B2B contact data decays at 2.1% per month, amounting to roughly 22.5% annually. This means a database that looked clean at the start of the year has lost nearly one in four records to changes by December.
The root causes are straightforward. People change roles, companies merge or relocate, phone numbers get reassigned after reorgs, and none of these are mistakes. They are the natural pace of business. The problem is that most B2B databases capture a moment in time and then sit still while the world moves around them.
The further this goes unchecked, the worse it gets. Emails start bouncing, calls go to people who left months ago, and reps spend time on leads that were never going to convert.
How to Solve It
Run continuous enrichment: Set up automated workflows that re-verify records every 60 to 90 days rather than waiting for a full database audit.
Pull data at the moment of request: Use a real-time data provider for active pipeline and target accounts rather than one that refreshes on a monthly or quarterly cycle.
Monitor job change signals: Track when key contacts change roles or companies so your team acts on the update immediately rather than discovering it weeks later.
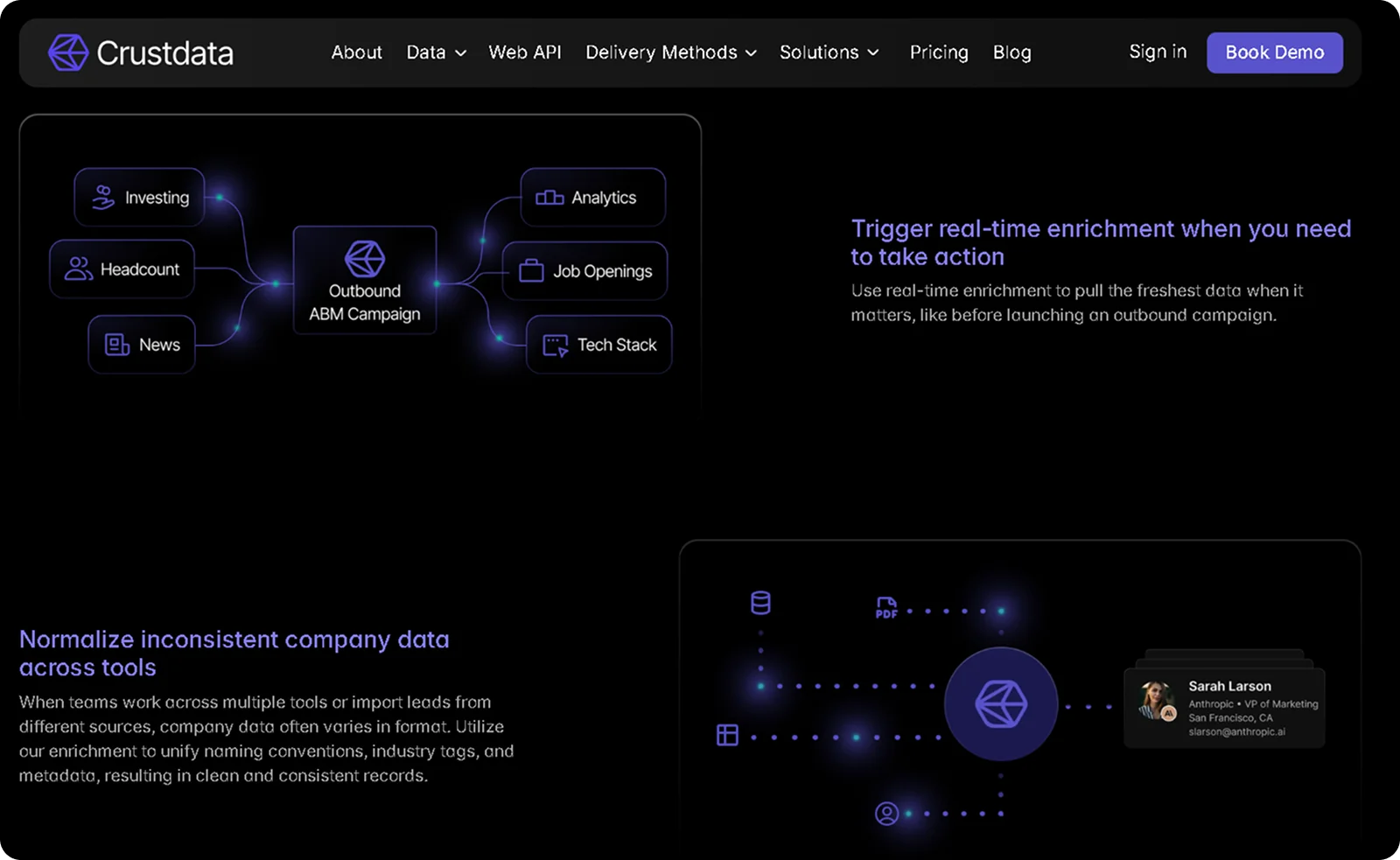
2. Inaccurate and Incomplete Data
Inaccurate and incomplete B2B data is contact or company information that is wrong, missing critical fields, or entered inconsistently at the point of collection. Most teams only discover the problem when a campaign underperforms, or a rep spends an afternoon chasing contacts who left the company months ago.
The root causes are small but cumulative. Forms with non-mandatory fields get submitted half-filled, reps enter contacts manually with typos, and third-party lists arrive unverified. Individually, these feel harmless, but across thousands of records, they create a database that appears complete but is not.
The downstream impact is concrete. SDRs cannot call without a direct dial, personalization fails without a job title, and lead scoring breaks without firmographic data like company size or industry.
How to Solve It
Validate at point of entry: Verify email addresses and phone numbers the moment a record enters your system, rather than cleaning them downstream after campaigns have already launched.
Enrich records to fill critical gaps: Use a data provider to append missing fields, including job title, company size, direct dial, and technology stack, before records reach your sales team.
Prioritize human verification for high-value accounts: Apply human-verified data for target accounts and senior contacts, as automated enrichment alone is not enough; human-verified data reduces the error rate on the fields that matter most.
3. Data Silos
Data silos occur when contact, account, and engagement data are stored in separate systems that do not communicate, resulting in each team having an incomplete and often contradictory view of the same customer. In most B2B organizations, marketing, sales, and finance each hold a different version of the same account with no live connection between them.
The pattern is familiar across most B2B organizations. Marketing tracks engagement in one tool, sales manages contacts in the CRM, and finance holds account data in a third system with no live connection between them. The result is that marketing sends campaigns to contacts, sales are already marked closed-lost, because no team has the full picture.
The problem compounds when data flows one way or not at all. A contact enriched in one system never updates in another, leaving the same record in three different versions with no clear source of truth.
How to Solve It
Connect systems through API-first infrastructure: Use a data layer that delivers consistent, enriched records to every tool in your stack simultaneously, rather than managing separate sync processes between individual platforms.
Eliminate platform lock-in: Avoid data providers that only integrate with their own ecosystem, since proprietary lock-in is one of the primary structural causes of silos.
Establish a single source of truth: Designate one system as the master record and ensure all enrichment, updates, and corrections flow from there outward to connected tools.
4. Lack of Data Standardization
Data standardization problems occur when the same information is recorded differently across systems, making it impossible to aggregate, deduplicate, or act on reliably. It is one of the quietest data challenges because individual records look fine in isolation, and the problem only surfaces when teams try to combine or analyze data at scale.
The root cause is usually a lack of enforced entry standards. One rep enters a phone number as (123) 456-7890, another uses 123-456-7890, and a third omits the country code entirely. One system stores a company as "IBM," while another stores it as "International Business Machines." Without a consistent schema, deduplication logic fails, and reporting produces conflicting numbers.
The downstream impact shows up in segmentation, lead scoring, and forecasting. If the same account exists under three different name formats across your CRM, marketing automation tool, and data warehouse, every report that references that account will be wrong.
How to Solve It
Enforce data entry standards before data enters any system: Define a single format for every field, including phone numbers, company names, and job titles, and build validation rules that reject non-compliant entries at the point of input.
Use structured API-delivered data: Receiving data from a provider that returns consistently formatted, schema-validated records removes the inconsistency that manual entry introduces.
Run deduplication on a regular cycle: Merge conflicting records using a defined hierarchy that determines which source takes priority when the same contact or account appears more than once.
5. Data Compliance and Privacy
Data compliance challenges arise when B2B teams collect, store, or use contact data in ways that conflict with regulations like GDPR, CCPA, or regional do-not-call requirements. GDPR violations can result in fines of up to 4% of annual global turnover, and the regulation applies to any company targeting EU residents, regardless of where that company is based.
The most common compliance failures in B2B are not deliberate. Teams buy contact lists without verifying consent, use data collected under one legal basis for a different purpose, or run outbound campaigns into markets where they have not screened against local do-not-call registries. Each of these can trigger a complaint or an investigation.
How to Solve It
Verify your data provider's compliance framework: Work only with providers that document their legal basis for data collection, screen against DNC lists in your target markets, and can produce an audit trail if challenged.
Maintain a record of data provenance: Know where every contact record came from, when it was collected, and under what legal basis it is being used for outreach.
Review data processing agreements regularly: As regulations change across jurisdictions, agreements with third-party data providers need to reflect current requirements, not the state of the law when the contract was signed.
6. Growing Data Operations
Managing B2B data at volume becomes a challenge when the processes a team uses to maintain quality simply were not built for the size the business has grown to. What worked for a few hundred contacts in a spreadsheet does not hold up across tens of thousands of records spread across a CRM, a marketing tool, and a data warehouse.
Manual cleanup that runs quarterly can keep a small database in reasonable shape, but the same approach applied at scale creates a backlog that compounds faster than any team can clear it. By the time one round of fixes is done, the next wave of decay has already started.
The real cost is everything that does not get done because the team is busy fixing records instead of using them to build a pipeline, improve segmentation, or analyze what is working.
How to Solve It
Replace manual enrichment with automated pipelines: Set up enrichment workflows that trigger automatically when new records enter your system and on a scheduled cycle for existing ones, removing the dependency on manual intervention.
Use webhook-based monitoring instead of scheduled polling: Rather than auditing your database on a fixed schedule, set up event-driven alerts that notify your team when a record changes so issues are caught as they happen.
Scale through API-based data delivery: High-volume queries require infrastructure that can handle them without additional headcount. Crustdata's Job Listing API and Watcher API are built for exactly this, delivering programmatic access to real-time data without manual exports or uploads.
7. Missing Real-Time Signals
Missing real-time signals means relying on static data that does not capture live events, showing when a prospect is actually ready to engage. A VP of Sales who joined a target account last week, or a hiring spike in engineering last month, are signals that open an outreach window, and most teams miss them entirely.
Static databases refresh monthly or quarterly, which means the signal has often passed by the time it appears in your CRM. The account looks the same as it did 30 days ago, but the buying context has shifted completely.
How to Solve It
Use a data provider that indexes live at the moment of request: Request data in real time so every record your team acts on reflects what is true right now, not what a database captured last month.
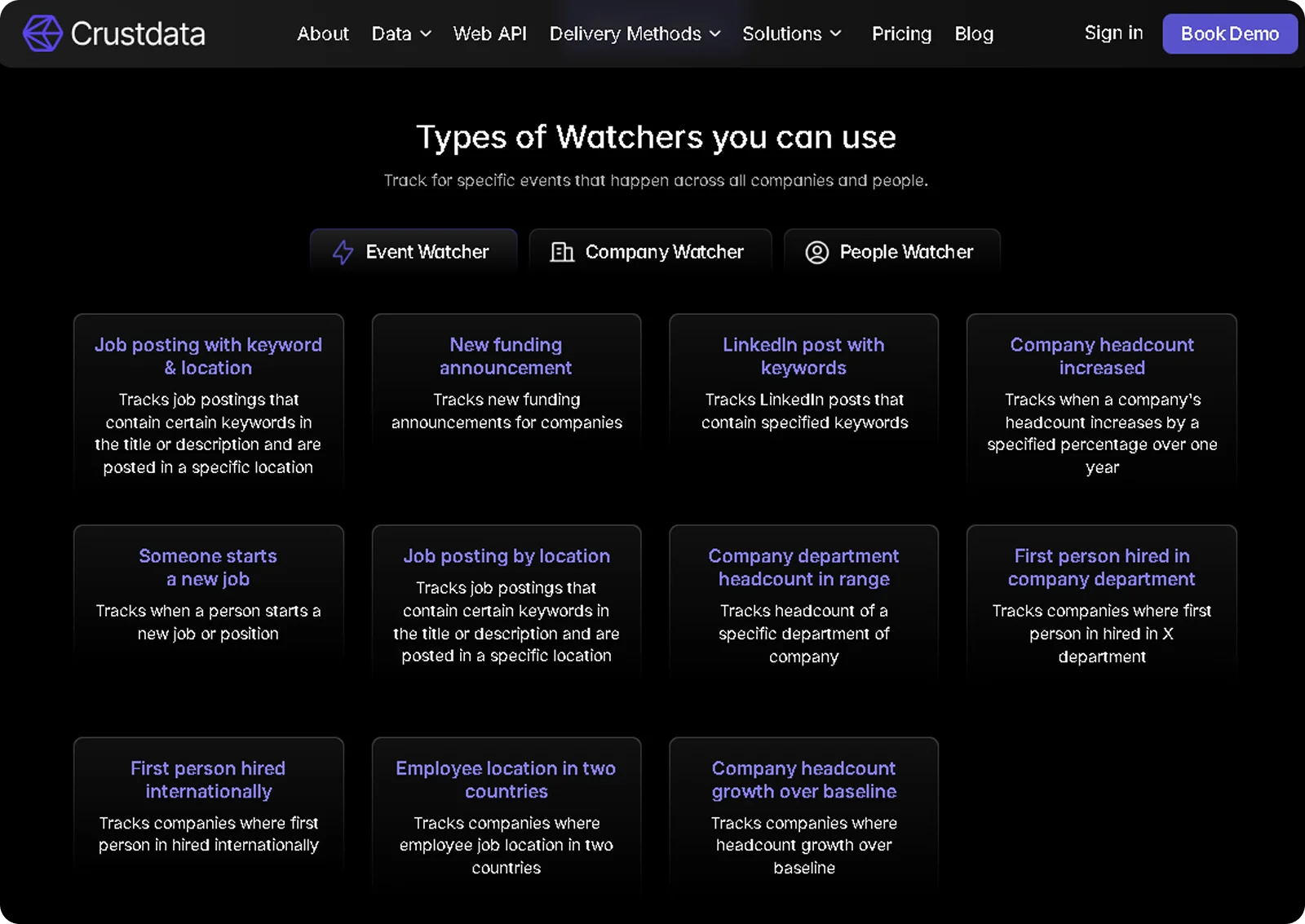
Set webhook-based alerts for trigger events: Configure notifications that fire the moment a tracked company posts a relevant new hire, closes a funding round, or spikes in headcount. Crustdata's Watcher API handles this natively, pushing alerts as soon as a relevant event fires.
Combine job posting data with company context: Pair hiring signals with funding stage, headcount trends, and technology stack to give your team the full picture before they reach out.
Why Crustdata Is Built for These B2B Data Challenges
The challenges above share a common root cause: data that is static, disconnected, and built around a snapshot rather than what is actually happening right now. Crustdata indexes the web continuously and delivers data at the moment of request, so your team never acts on a record that is already out of date.
With Crustdata, you can:
Enrich company and people records in real time across 250+ company fields and 90 people fields, pulled live at the moment of request rather than from a periodically refreshed database.
Monitor target accounts for live trigger events, including funding rounds, job changes, and headcount spikes, via the Watcher API, which sends webhook alerts the moment they happen.
Build hyper-targeted prospect lists using 60+ people filters and 95+ company filters, including seniority, geography, past companies, and technology adoption.
Integrate with any CRM, ATS, or sales tool via clean REST APIs with no platform lock-in, eliminating the proprietary silos that trap data inside a single vendor’s ecosystem.
Access 1 billion+ people profiles and 60 million companies aggregated from 15+ verified sources, with dedicated engineering support per account.
How much of your pipeline is built on records that are already out of date?
Book a demo to find out what your pipeline looks like with a live data layer underneath it.
Frequently Asked Questions on B2B Data Challenges
What is the most common B2B data challenge?
Data decay is the most pervasive because it affects every other challenge on this list. Even a database that starts clean becomes inaccurate over time as contacts change jobs, companies restructure, and details shift. Teams that are not actively enriching their records fall further behind every month, and the other six challenges become harder to manage as a result.
How much does bad data cost a business?
According to Gartner, poor data quality costs organizations an average of $12.9 million annually. The damage comes from multiple directions: wasted campaign spend, sales time lost to wrong numbers and outdated contacts, and strategic decisions made on inaccurate information.
What is the difference between data decay and data inaccuracy?
Data decay is a time-based problem: accurate data that becomes outdated as the world changes. Data inaccuracy is an entry-based problem: data that was wrong or incomplete from the moment it was collected. Both produce records that cannot be trusted, but they require different fixes. Decay requires continuous enrichment and monitoring over time, while inaccuracy requires validation and verification at the point of entry.


Products
Popular Use Cases
Competitor Comparisons
Use Cases
95 Third Street, 2nd Floor, San Francisco,
California 94103, United States of America
© 2026 Crustdata Inc.
Products
Popular Use Cases
Competitor Comparisons
Use Cases
95 Third Street, 2nd Floor, San Francisco,
California 94103, United States of America
© 2025 CrustData Inc.
Products
Popular Use Cases
Competitor Comparisons
Use Cases
95 Third Street, 2nd Floor, San Francisco,
California 94103, United States of America
© 2026 Crustdata Inc.