How to Build Internal Deal Sourcing, Founder Discovery, and Portfolio Monitoring Tools
A reference architecture for internal investor tools: one real-time data layer, an entity-resolution layer, and three queries for deal sourcing, founder discovery, and portfolio monitoring, orchestrated by a Claude Code agent or a direct API script.
Published
Written by
Manmohit Grewal
Reviewed by
Abhilash Chowdhary
Read time
7
minutes

"I could spend my days maintaining scrapers and warming up accounts, but it's just not the best use of my time." That is a sourcing lead at a tier-one VC describing the in-house LinkedIn scraper they had been keeping alive quarter after quarter to feed a sourcing dashboard. They needed a different system underneath the dashboard, rather than a different vendor or a better sourcing tool at the same layer.
Deal sourcing, founder discovery, and portfolio monitoring are three saved views on top of one data pipeline, and treating them that way is what keeps the build maintainable as the firm grows. The working shape is a real-time company and people data layer underneath, a small entity-resolution layer on top of it, and three queries reading from the same store. An investor with Claude Code and an MCP-exposed company data API can ship this in an afternoon.
Two things changed in 2025 and 2026 that make this build cheap. Real-time company and people data layers matured past PitchBook and Crunchbase on the dimensions investors care about today (freshness, stealth coverage, webhook delivery, API depth), and Claude Code plus the Model Context Protocol collapsed the engineering-hour cost of wrapping a data API into a working internal tool. The concrete build pattern is a short set of configuration files (a thesis, a scoring skill, a rubric) that a Claude Code agent reads on every invocation against a real-time company database, producing ranked candidates with firm-voice rationales.
One data layer, three tools: the system architecture
All three tools ask the same underlying question (what just changed about this company or this person) against different universes. Deal sourcing aims at your investable universe outside the pipeline, founder discovery aims at people whose career signals suggest they are about to start something, and portfolio monitoring aims at the companies and people you already invested in. The architecture that serves all three cleanly has four layers.
Data layer. A real-time company search and enrichment API plus a real-time people search and enrichment API plus a webhook layer for push-based signals. Crustdata's Company Search API offers 95+ filters across size, geography, industry, funding stage, growth, investors, and web presence. People Search runs across 1B+ profiles with 60+ filters and nested boolean logic. Watcher delivers webhook notifications for job changes, promotions, social posts, company job postings, funding events, press mentions, and headcount-growth thresholds. These are hosted APIs that your build queries against, which means the in-house work is everything above them.
Entity resolution layer. Canonical identifiers for companies and people across providers, your CRM, and the portfolio tracker. The section below covers this in depth, because skipping it is how internal tools quietly drift wrong within a sprint.
Query layer. Three saved views. A deal-sourcing filter (new companies matching thesis), a founder-discovery filter (people whose signals suggest stealth or upcoming founding), and a portfolio watchlist (the companies you own and their key people). All three queries hit the same data layer and resolve through the same identifiers.
Agent layer. The thin wrapper that turns the queries into something a human or an automated workflow acts on. A Claude Code agent with Crustdata's MCP server configured reads a thesis file, a scoring skill, and the query result, then writes a rationale to wherever your pipeline lives (Attio, HubSpot, Salesforce, a Postgres table, a Notion page, or the Slack channel the partner actually reads). You can also run the same logic by calling the Crustdata API directly from a Python or Node script if you prefer not to route through an MCP client.
Asking the data layer for a deal-sourcing slice, using Crustdata's Company Search endpoint:
import httpx response = httpx.post( "https://api.crustdata.com/screener/company/search", headers={"Authorization": f"Token {CRUSTDATA_TOKEN}"}, json={ "filters": [ {"filter_type": "INDUSTRY", "type": "in", "value": ["Artificial Intelligence"]}, {"filter_type": "HEADCOUNT", "type": "between", "value": [10, 40]}, {"filter_type": "LAST_FUNDING_STAGE", "type": "in", "value": ["Series A"]}, {"filter_type": "HQ_REGION", "type": "in", "value": ["United States"]}, {"filter_type": "JOB_OPENINGS_TITLE", "type": "contains", "value": "AI Engineer"}, ], "page": 1 }, ) companies = response.json()["profiles"]
import httpx response = httpx.post( "https://api.crustdata.com/screener/company/search", headers={"Authorization": f"Token {CRUSTDATA_TOKEN}"}, json={ "filters": [ {"filter_type": "INDUSTRY", "type": "in", "value": ["Artificial Intelligence"]}, {"filter_type": "HEADCOUNT", "type": "between", "value": [10, 40]}, {"filter_type": "LAST_FUNDING_STAGE", "type": "in", "value": ["Series A"]}, {"filter_type": "HQ_REGION", "type": "in", "value": ["United States"]}, {"filter_type": "JOB_OPENINGS_TITLE", "type": "contains", "value": "AI Engineer"}, ], "page": 1 }, ) companies = response.json()["profiles"]
import httpx response = httpx.post( "https://api.crustdata.com/screener/company/search", headers={"Authorization": f"Token {CRUSTDATA_TOKEN}"}, json={ "filters": [ {"filter_type": "INDUSTRY", "type": "in", "value": ["Artificial Intelligence"]}, {"filter_type": "HEADCOUNT", "type": "between", "value": [10, 40]}, {"filter_type": "LAST_FUNDING_STAGE", "type": "in", "value": ["Series A"]}, {"filter_type": "HQ_REGION", "type": "in", "value": ["United States"]}, {"filter_type": "JOB_OPENINGS_TITLE", "type": "contains", "value": "AI Engineer"}, ], "page": 1 }, ) companies = response.json()["profiles"]
You get back a list of companies that match the filter. The next call passes those company_id values into a People Search to find their founders, their first 20 engineers, and whoever is hiring for them. The call after that creates a Watcher on the same set to fire webhooks when headcount or leadership changes. An engineer at a US growth-stage VC described the pain this replaces: "10 isolated and idempotent data integrations, and I would love if we could pay a service to get all of these services into a single source of truth."
You can sign up for Crustdata's free tier (100 credits included) to see the actual responses before committing to a build.
Deal sourcing: the outward-looking query
Deal sourcing works as a running query against the outside universe, pointed at the criteria your fund actually invests on, with a scoring agent that reads your thesis and writes a rationale.
The loop runs in five stages: a Company Search filters the investable universe, a scoring skill ranks each match against the fund's written thesis, the highest scorers land on a watchlist, a Watcher is created over that set so the system fires when anything important changes on any watchlist company, and the agent reruns on every change to rescore and notify.
Two details make this work in practice. The scoring step outputs a rationale, so partners receive a paragraph about why the company fits your thesis rather than a number ranking it against a median-fund template (the reason peer funds get alerted on the same PitchBook move is that PitchBook shows everyone the same rank). And the "watchlist" lives as a persistent saved search plus a persistent Watcher, so the set updates on its own rather than sitting as a static CRM tag a partner pasted in last month.
A sourcing lead at a tier-one VC told us that Harmonic data was up to a month stale on a company they were tracking, which is long enough for a peer fund already closer to the founder to issue a term sheet. The build pattern closes that gap by reading from a data layer whose freshness is measured in hours not weeks.
A stripped-down scoring skill looks like this:
# scoring_skill.py (invoked by a Claude Code agent) def score_company(company: dict, thesis: str, rubric: str) -> dict: prompt = f""" Thesis: {thesis} Rubric: {rubric} Company: {company} Return: a JSON object with `score` (0-100), `top_signals` (list), and `rationale` (3-5 sentences, firm-voice). """ return llm.complete(prompt, format="json")
# scoring_skill.py (invoked by a Claude Code agent) def score_company(company: dict, thesis: str, rubric: str) -> dict: prompt = f""" Thesis: {thesis} Rubric: {rubric} Company: {company} Return: a JSON object with `score` (0-100), `top_signals` (list), and `rationale` (3-5 sentences, firm-voice). """ return llm.complete(prompt, format="json")
# scoring_skill.py (invoked by a Claude Code agent) def score_company(company: dict, thesis: str, rubric: str) -> dict: prompt = f""" Thesis: {thesis} Rubric: {rubric} Company: {company} Return: a JSON object with `score` (0-100), `top_signals` (list), and `rationale` (3-5 sentences, firm-voice). """ return llm.complete(prompt, format="json")
The Claude agent reads the thesis file for the fund's criteria, the rubric for the scoring weights, and the enriched company record from the data layer, then writes the response back to the CRM row alongside the source signals and reruns on the next webhook fire.
Founder discovery: finding people before they start
Founder discovery is the same pipe pointed at people. You move from "which companies match the thesis" to "which people are about to start a company that will match the thesis."
The signals that work in 2026 are well-known and not well-operationalized:
Employees leaving specific tech companies with a specific shape (AI-lab research scientists, late-stage fintech product leads, ex-founder repeats)
First-20-engineer pedigree, framed by a public investor-operator as "who are the first 20 engineers, what were their previous jobs, when were they in those previous jobs, GPAs, basically what are all the signals about how high-quality an engineer is"
Alumni-tenure combinations (Stanford PhDs who stayed at DeepMind for 3-plus years, say)
Every item above is a People Search filter and a Watcher subscription, and the craft is in combining them rather than in any single one. A People Search query that combines "people who left [target-company-set] in the last 90 days," "current title null or contains 'founder' or 'stealth'," and "previous experience includes [target-skill-set]" runs in one API call and resolves to a ranked list.
The catch is entity resolution, which shows up first on the founder side. An accelerator ops lead told us "Carnegie Mellon reads 20 different ways on LinkedIn," and their founder-discovery pipeline leaked candidates for months until they fixed the resolver layer covered below.
One public build worth studying is the stealth-founder tracking pattern Crustdata documented, which uses job-change Watchers on target companies plus a People Search for "current company is null and previous company is [target]" to surface exits into stealth before the resulting companies have a website. Watchers fire on state changes (headcount of one to two, a new LinkedIn page, a new domain) before any database-of-record has a row to index, which matters because stealth founders are pre-company by definition and do not show up in corporate registries at all until they go public with a website or funding round.
Portfolio monitoring: the live-capture problem
Portfolio monitoring is miscast as a dashboard problem when it is actually a capture problem. A platform lead at an early-stage fund told us "our biggest frustration is the inability to see social posts from our founders," and a common shape in the r/venturecapital threads is that the fund pays $80,000 per year for a portfolio-monitoring platform while the numbers for the quarterly IC meeting still come from an associate pinging portfolio CEOs in Slack on Thursday night. The dashboard itself is usually fine, and the missing piece is that nothing is watching the portfolio between Thursdays. You almost certainly should not replace the dashboard, because LP reporting already expects a specific layout. What you build underneath it is a live-capture layer made of five parts.
Portfolio watchlist. A saved list of portfolio company IDs and key-person IDs. This is one line of code, or a small manual table, and it is the universe Watchers fire on.
Watcher subscriptions. Push webhooks for headcount changes, leadership departures, new funding rumors, press mentions, job postings, and social posts from founders, delivered on subscription rather than on a polling cadence you have to manage.
HMAC verification plus idempotency. The webhook receiver verifies the payload signature with your shared secret and uses an idempotency key (e.g., {watcher_id}:{event_id}) to dedupe replays. This is basic production hygiene and is worth writing once.
Routing. The Watcher fans out into whatever surfaces the partners already use, which in most firms means a single Slack channel the deal partner already reads, a row write into the existing dashboard's data store, and an email digest for the Monday partner meeting.
Enrichment on demand. When a signal fires, the agent runs a fresh People Enrichment or Company Enrichment on the affected record so the partner reads the up-to-date context instead of last quarter's cache. Crustdata's Watcher product is designed for this loop and simulates events for integration testing before you wait for real ones.
The outcome is that the Thursday-night Slack goes away, the associate stops being the pipeline, and the same dashboard the LP sees pulls from a live feed instead of a manual capture. How a top-5 VC by AUM built an internal deal-sourcing tool with Crustdata is a public reference for the same pattern at a larger fund.
Entity resolution: the week-two bottleneck
Entity resolution is where internal tools quietly drift wrong inside a quarter. The failure mode looks like this: you pull a company list from PitchBook, you pull enriched people records from a real-time people API, you join on company_name, and your join rate is 64%. The other 36% reads as missing when the record is actually there, just spelled differently.
A name-only join reads "Anthropic," "anthropic.com," "Anthropic, PBC," and "Anthropic Inc" as four separate companies, the same way it treats "Carnegie Mellon University," "CMU," "Carnegie Mellon," and "Carnegie Mellon Univ." as four separate schools. A data engineer at a multi-stage fund said it plainly: "No good unique identifiers to be able to join these data sets on. Still a huge problem."
The pattern that works has four components.
Deterministic keys first. Start with the strongest canonical identifier available. For companies, the domain (anthropic.com) and the LinkedIn company URL are both strong. For people, the LinkedIn profile slug is the strongest. Where possible, the Crustdata company ID or person ID provides a canonical integer anchor across all calls to the same data layer.
Fuzzy fallback with thresholds. Where deterministic keys are missing, a fuzzy match on (normalized name, geography, industry) works for companies and (normalized name, employer, graduation year) works for people. Use a library like rapidfuzz and set a confidence threshold so that anything below it queues for human review rather than auto-merging.
Provenance tags. Every field on a merged record carries the provider and the date it was last fetched. When two providers disagree on headcount, you know which to trust because the record remembers who said what and when. Provenance also gives you a time series for free, since concatenating fetches over time reconstructs the history of how a field moved, which is how you answer questions like when a portfolio company started building its sales team without subscribing to a separate time-series product.
Human-in-the-loop queue. Matches below the confidence threshold go to a lightweight review UI (a Slack message with "A or B or neither?" buttons, a Notion table, whatever your fund already has) so the ops lead can resolve edge cases without being the full pipeline.
A concrete shape for the resolver:
def resolve_company(raw: dict, canonical_db) -> MatchResult: if raw.get("domain"): hit = canonical_db.lookup_by_domain(raw["domain"]) if hit: return MatchResult(hit, confidence=1.0, method="domain") if raw.get("profile_url"): hit = canonical_db.lookup_by_profile(raw["profile_url"]) if hit: return MatchResult(hit, confidence=1.0, method="profile") candidates = canonical_db.fuzzy_search( normalize(raw["name"]), raw.get("hq_country") ) best = candidates[0] if candidates else None if best and best.score >= 0.92: return MatchResult(best, confidence=best.score, method="fuzzy") return MatchResult(None, confidence=0.0, method="review_queue")
def resolve_company(raw: dict, canonical_db) -> MatchResult: if raw.get("domain"): hit = canonical_db.lookup_by_domain(raw["domain"]) if hit: return MatchResult(hit, confidence=1.0, method="domain") if raw.get("profile_url"): hit = canonical_db.lookup_by_profile(raw["profile_url"]) if hit: return MatchResult(hit, confidence=1.0, method="profile") candidates = canonical_db.fuzzy_search( normalize(raw["name"]), raw.get("hq_country") ) best = candidates[0] if candidates else None if best and best.score >= 0.92: return MatchResult(best, confidence=best.score, method="fuzzy") return MatchResult(None, confidence=0.0, method="review_queue")
def resolve_company(raw: dict, canonical_db) -> MatchResult: if raw.get("domain"): hit = canonical_db.lookup_by_domain(raw["domain"]) if hit: return MatchResult(hit, confidence=1.0, method="domain") if raw.get("profile_url"): hit = canonical_db.lookup_by_profile(raw["profile_url"]) if hit: return MatchResult(hit, confidence=1.0, method="profile") candidates = canonical_db.fuzzy_search( normalize(raw["name"]), raw.get("hq_country") ) best = candidates[0] if candidates else None if best and best.score >= 0.92: return MatchResult(best, confidence=best.score, method="fuzzy") return MatchResult(None, confidence=0.0, method="review_queue")
Around fifteen lines of resolver logic is what separates a tool the partners trust from one they quietly stop opening, and the rule is to build the resolver alongside the first query rather than after the joins start leaking.
Choosing a data layer: real-time APIs, bulk datasets, and the incumbents
The build pattern assumes a data layer underneath it, and most of the practical tradeoffs come down to which layer you pick.
Provider | Freshness cadence | Private / stealth coverage | Webhook delivery | API-first depth | Best For |
|---|---|---|---|---|---|
Weeks to quarters, registry-heavy | Strong on priced rounds, thin on stealth | None (export only) | Limited; dashboard-first | Funds whose workflow centers on priced-round data and LP reporting that expects PitchBook numbers. | |
Crunchbase | Days to weeks | Decent on announced rounds | Limited via partnerships | Partial API, dashboard-first | Teams whose primary need is funding-announcement coverage plus editorial context, where freshness past the week mark is acceptable. |
Days | Strong on headcount and hiring via LinkedIn-derived data | Partial webhook product | Strong API and bulk datasets | Builders who want bulk datasets for seeding plus APIs for ongoing enrichment, with headcount and hiring as primary signals. | |
Harmonic | Days, variable on fast-moving sectors | Claimed stealth coverage, user reports of lag | Limited | Strong API | Funds whose target universe moves slower than a month, where the "Harmonic up to a month stale" signal suggests caution on AI and crypto. |
Dealroom | Weeks | Good on European stealth | Partial | Partial | Funds with European coverage as a primary need, willing to accept the weekly cadence for broader ecosystem data. |
Days to weeks | Middle-market private companies, thinner on early-stage | Limited | Partial API plus workflow layer | Teams that want ICP-search on mid-market private companies plus a light workflow UI, without a builder architecture. | |
Apollo | Days | Sales-contact-centric, thin on firmographics for investors | Limited | Strong API | Teams using the same data layer for both deal sourcing and outbound contact, where it is weaker on investor-specific firmographics. |
Live for API, monthly to yearly for bulk | Strong on real-time signals, with stealth founders surfaced via Watchers on state changes | Full Watcher product with company, people, and event watchers, plus simulation endpoints for integration testing | 95+ company filters, 60+ people filters, MCP server, bulk dataset delivery alongside live API | Investment teams building the one-data-layer, three-tools architecture described here, along with funds whose advantage depends on signal freshness and webhook delivery into internal systems. |
The tradeoffs compound across three axes, with bulk datasets winning on cost-per-record for seeding and backfill, live APIs winning on deal sourcing and founder discovery where the question is "what changed in the last 24 hours," and webhooks being what makes portfolio monitoring work at all, since polling 40 companies hourly across three providers gets expensive fast and still misses events between polls. A mid-stage fund's platform team described the mature shape after their own build: they "actually use Crustdata now as a fallback mechanism" alongside other providers, so one primary layer plus one fallback plus enough entity resolution to merge them cleanly is what most working systems settle on.
A reference architecture: the complete build
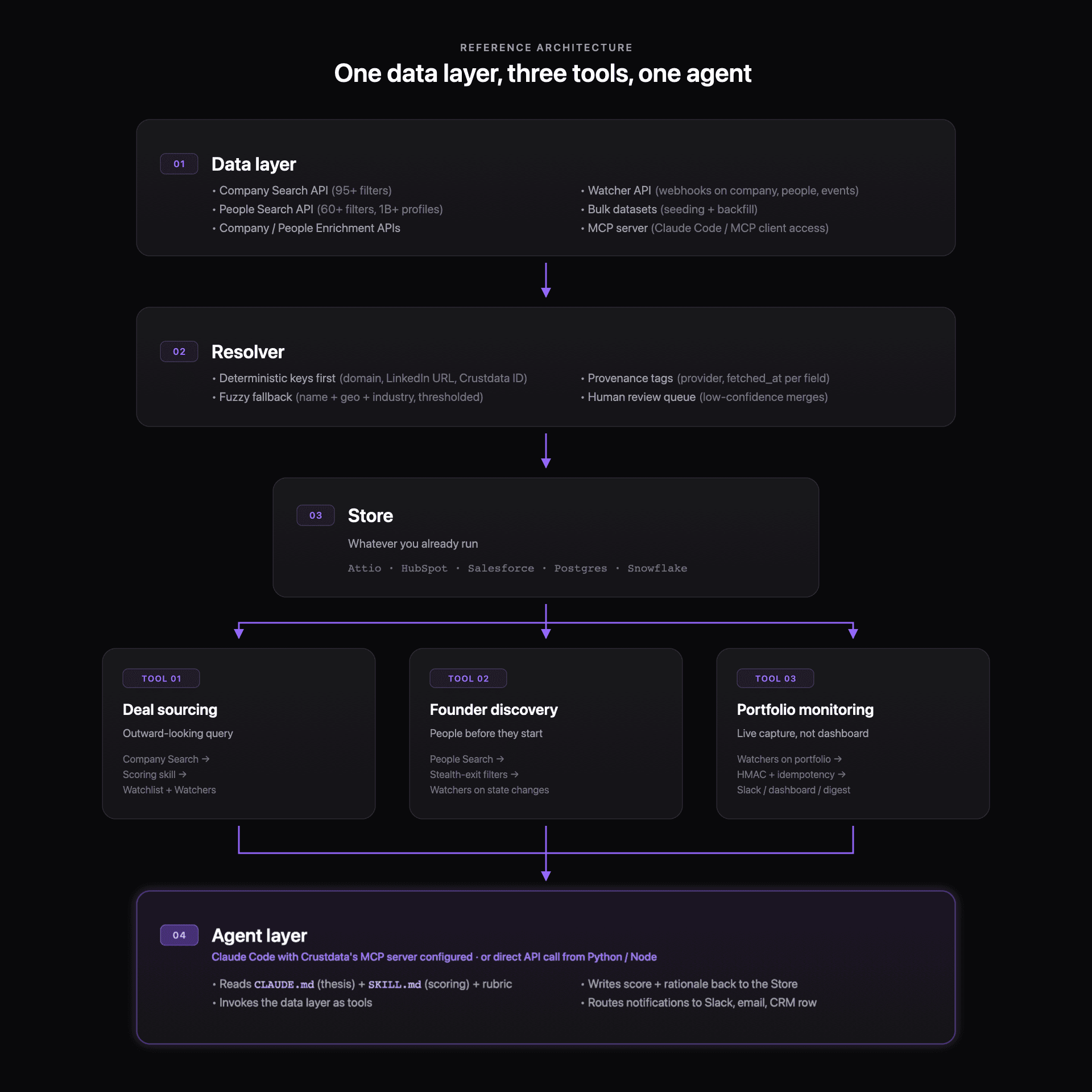
A 4-person fund running the full architecture on a few hundred API calls per month plus Watchers on a 40-company portfolio plus a People Search watchlist of a few hundred target founders sits in the low four figures per month, whereas the comparable bundled subscription (PitchBook plus a portfolio-monitoring vendor plus a LinkedIn scraper plus a contact enrichment layer) runs past $150,000 per year before engineering time on the scraper.
For a growth-stage fund with a 200-company portfolio and a 5,000-company universe, the API bill rises into mid five figures per year and still undercuts the bundle. The per-seat subscription model scales worse than linearly (partners pay a seat even when they do not open the dashboard), whereas the data-layer cost scales with the work and the thesis file stays one file.
Getting started: five concrete first steps
1. Write your CLAUDE.md thesis file. One page covering what your fund invests in and what it does not: sectors, stages, geographies, check sizes, the founder pedigree you weight, and the specific non-negotiables (revenue multiples, team composition, market maturity). This is the file your future agent reads on every invocation, so version it.
2. Write one scoring skill. A SKILL.md that takes an enriched company record, reads the thesis and the rubric, and emits a 0–100 score plus a 3–5 sentence rationale in your firm's voice. Start with the crudest possible prompt, iterate it against 20 companies your fund already has opinions on (your last quarter's pipeline), and tune until the scores match partner judgment 70% of the time. The goal is a first-pass filter that flags companies worth partner attention, nothing more.
3. Wire the data layer and run the skill on 50 companies. You have two paths. Install the Crustdata MCP server and point your Claude Code agent at it for the zero-code option, or call the Crustdata API directly from a Python or Node script if you prefer to write the orchestration yourself. Either way, run the scoring skill on 50 companies from your last quarter's pipeline and compare scores to outcomes (did you meet? did you invest?). The calibration loop is your build's first feedback signal.
4. Turn on Watchers for the portfolio set. Create company and people Watchers for every portfolio company and every key-person profile. Point them at one Slack channel the partners actually read. Verify HMAC signatures on the webhook receiver and dedupe on an idempotency key so a replay does not double-notify. Your Thursday-night Slack stops being necessary within a week.
5. Shadow-run against your existing stack for two weeks. Do not cut the vendor yet. Run the build in parallel (whether you chose the MCP client path or the direct API path in step 3), log every company it surfaces that the incumbent missed, every portfolio event it caught first, every false positive it produced. At two weeks, the partners decide whether the vendor renewal or the build is the expensive question.
Conclusion
Entity resolution is the hard part of this build, and the rule is to do it alongside the first query rather than after the partners start losing faith in the output. The rest is plumbing. You need a one-page thesis file, a scoring skill, a Claude Code agent pointed at Crustdata's MCP server (or a direct API integration if you prefer to write the orchestration yourself), and Watchers on your portfolio. Run it on your last quarter's pipeline and compare scores to outcomes, or book a demo if you want us to walk through the architecture against your stack.



Products
Popular Use Cases
Competitor Comparisons
Use Cases
95 Third Street, 2nd Floor, San Francisco,
California 94103, United States of America
© 2026 Crustdata Inc.
Products
Popular Use Cases
Competitor Comparisons
Use Cases
95 Third Street, 2nd Floor, San Francisco,
California 94103, United States of America
© 2025 CrustData Inc.
Products
Popular Use Cases
Competitor Comparisons
Use Cases
95 Third Street, 2nd Floor, San Francisco,
California 94103, United States of America
© 2026 Crustdata Inc.