How to Build Internal Recruiting and Candidate Sourcing Tools with Real-Time People Data
The architecture, APIs, and webhook patterns for building an internal recruiting and candidate sourcing tool on real-time people data, drawn from 75+ buyer calls with teams who've shipped.
Published
Written by
Manmohit Grewal
Reviewed by
Abhilash Chowdhary
Read time
7
minutes

How to Build Internal Recruiting and Candidate Sourcing Tools with Real-Time People Data
"Horrific. Every CV looks different." That is how one mid-market staffing agency's internal sourcing team describes what it feels like to search their legacy ATS on a Monday morning, when they need to pull a shortlist of candidates and every profile in the system is formatted a different way. Across 75+ calls with recruiting teams building their own internal tools, the phrase that came up more than any other was stitching, meaning the daily act of moving a candidate between five or six systems and losing context at every hop. Another recurring line from those interviews was that recruiting technology today is "substantially the same as it was 25 years ago," and the way around that is to build. A real-time search layer fixes exactly this, which is what we build step by step in building a custom candidate search engine.
This guide is for teams that have already decided to build an internal recruiting tool. It assumes you have weighed build versus buy and landed on build, and it skips past the motivational layer to show the architecture, APIs, webhook patterns, and ATS write paths that make an internal recruiting and candidate sourcing system work. The stack here assumes real-time people data (live APIs, not a database refreshed monthly), standing signal watchers that replace nightly scrapes, and an ATS round-trip that keeps recruiters inside one system instead of twelve.
What follows is ordered the way you will actually ship it, starting with architecture, then moving through enrichment, passive-candidate signals, precision search, and ATS integration, and closing with the reference diagram and five concrete first steps.
Why teams are building instead of buying another point solution
We see a pattern across these 75 calls. Teams we spoke with scale into a new vertical or region, get tired of running a brittle scraper stack, and look for a data layer they can call from their own application. Others find that the major recruiter-database products do not cover the long tail of roles they need to source for, so they start wiring together a smaller tool using APIs their engineering team can run in a week. One agency founder we interviewed said their recruiter software was "a glorified job board" and they already knew how to build what they actually needed.
The cost math has shifted. Claude Code and similar AI coding tools mean that a two-person team, a product lead and one engineer, can now ship a working sourcing-enrichment-signal loop in a few sprints. The build now looks like writing glue code on top of a handful of documented APIs, which is why what used to require an engineering org now requires one engineer and some product taste. The build vs buy decision for internal recruiting infrastructure tilts further toward build every quarter as AI coding tools shorten the shipping timeline.
Internal sourcing system architecture
Every working internal recruiting tool we have seen in buyer calls, from agency-built candidate platforms to in-house TA sourcing tools, breaks down the same way. The four layers that matter are search, enrichment, signal, and workflow. They stay loosely coupled in the good designs we have reviewed, which is what lets you swap any one layer for a different vendor without rewriting the other three whenever pricing, coverage, or priorities shift.
Search answers the question "who fits this role right now?" It runs against a live people index with 60+ filters (skills, current title, tenure, education, certifications, location), plus a company index you can use to narrow by account, industry, size, and headcount growth. Search is a function you call from your workflow layer every time a new requisition opens or a new trigger fires, rather than a one-time stored query.
Enrichment answers "what do we know about this person, aggregated from every public source?" This is where professional networks, developer profiles, technical Q&A sites, social timelines, portfolios, and public resumes get unified into one canonical profile. Enrichment in your own system (as opposed to a hosted no-code dashboard) means you own the waterfall logic, the credit accounting, and the cache.
Signal answers "what changed since we last looked?" Job changes, profile edits, funding events on the candidate's employer, hiring sprees, and promotions are all signal types that should flow into your system as webhooks, not as nightly batch refreshes. The Crustdata Watcher API is one way to get these; if you subscribe to a signal-alert recruiting tool today, you are paying for a thin wrapper over a similar signal feed.
Workflow is the recruiter-facing layer. This is your ATS write-back, your outbound sequencer integration, your scoring logic, and your Slack or email notifier. Most of the custom code in a well-built internal tool lives here, because this is where your team's actual process gets encoded.
The code example below shows what the first call in this architecture looks like in practice. If you are sourcing senior backend engineers at growing Series B to Series D fintech companies in the US, your first move is to find the fintechs that are hiring and growing, then pass those companies into People Search. Company Search is the documented entry point:
curl -X POST https://api.crustdata.com/screener/companydb/search \ -H "Authorization: Token $CRUSTDATA_TOKEN" \ -H "Content-Type: application/json" \ -d '{ "filters": { "op": "and", "conditions": [ { "filter_type": "industries", "type": "(.)", "value": "Financial Services" }, { "filter_type": "hq_country", "type": "=", "value": "USA" }, { "filter_type": "employee_count_range", "type": "in", "value": ["51-200", "201-500", "501-1000"] }, { "filter_type": "last_funding_round", "type": "in", "value": ["Series B", "Series C", "Series D"] }, { "filter_type": "employee_metrics.growth_12m_percent", "type": ">", "value": 15 } ] }, "limit": 200, "sorts": [{ "column": "employee_metrics.growth_12m_percent", "order": "desc" }] }'
curl -X POST https://api.crustdata.com/screener/companydb/search \ -H "Authorization: Token $CRUSTDATA_TOKEN" \ -H "Content-Type: application/json" \ -d '{ "filters": { "op": "and", "conditions": [ { "filter_type": "industries", "type": "(.)", "value": "Financial Services" }, { "filter_type": "hq_country", "type": "=", "value": "USA" }, { "filter_type": "employee_count_range", "type": "in", "value": ["51-200", "201-500", "501-1000"] }, { "filter_type": "last_funding_round", "type": "in", "value": ["Series B", "Series C", "Series D"] }, { "filter_type": "employee_metrics.growth_12m_percent", "type": ">", "value": 15 } ] }, "limit": 200, "sorts": [{ "column": "employee_metrics.growth_12m_percent", "order": "desc" }] }'
curl -X POST https://api.crustdata.com/screener/companydb/search \ -H "Authorization: Token $CRUSTDATA_TOKEN" \ -H "Content-Type: application/json" \ -d '{ "filters": { "op": "and", "conditions": [ { "filter_type": "industries", "type": "(.)", "value": "Financial Services" }, { "filter_type": "hq_country", "type": "=", "value": "USA" }, { "filter_type": "employee_count_range", "type": "in", "value": ["51-200", "201-500", "501-1000"] }, { "filter_type": "last_funding_round", "type": "in", "value": ["Series B", "Series C", "Series D"] }, { "filter_type": "employee_metrics.growth_12m_percent", "type": ">", "value": 15 } ] }, "limit": 200, "sorts": [{ "column": "employee_metrics.growth_12m_percent", "order": "desc" }] }'
The response returns a list of company records with company_id, company_name, hq_location, headcount metrics, and a next_cursor you use for pagination. You feed those company IDs into your People Search call as a filter (current_company_id in [...]) and narrow further by role, tenure, skills, and location. The whole hop from "growing fintechs with recent funding" to "senior backend engineers at those fintechs" is two API calls and a handful of filters.
Everything else in the architecture branches off these two calls.
Candidate enrichment and profile unification
Enrichment is the part where most teams reach for a no-code enrichment dashboard and stop. You do not have to. The pattern those tools use (try Provider A, fall through to Provider B on empty, refund the credit on miss) is roughly 80 lines of Python. Teams who have called this pattern a "waterfall" for years in outbound GTM are importing it into recruiting now.
The core loop looks like this:
You start with a limited seed: an email, a professional-network URL, a first-plus-last name and company, or a developer-site handle.
You call your primary People Enrichment API to resolve the seed to a full profile with 90+ datapoints (role, full work history, education, skills, certifications, social URLs, and contact information where available).
If a specific field is missing (for example, a developer-site handle or a personal email), you call a secondary provider.
You merge the result into your canonical profile schema, keeping a provenance tag on each field so you know where it came from and when.
You cache the profile and re-enrich on a schedule or a trigger (new job signal, new role posting).
One staffing team described the problem a waterfall solves in a sentence: "a hundred different systems with different data, and they don't speak to one another." When profiles arrive from CV parsers, social scrapers, job boards, and referral chatbots, the schemas drift. The waterfall pattern rescues this because you define one canonical schema and write one adapter per source. A technical recruiting agency we spoke to, which enriches professional profiles with developer-site signals and public portfolios for technical roles, described essentially the same architecture.
A minimal waterfall in your own code looks like:
def enrich(seed): profile = canonical_schema() for provider in [primary, secondary, tertiary]: fields = provider.lookup(seed) profile.merge(fields, provenance=provider.name) if profile.is_complete(): break return profile
def enrich(seed): profile = canonical_schema() for provider in [primary, secondary, tertiary]: fields = provider.lookup(seed) profile.merge(fields, provenance=provider.name) if profile.is_complete(): break return profile
def enrich(seed): profile = canonical_schema() for provider in [primary, secondary, tertiary]: fields = provider.lookup(seed) profile.merge(fields, provenance=provider.name) if profile.is_complete(): break return profile
That is the whole trick. The "magic" of the hosted enrichment dashboards is the credit ledger and the no-code UI, both of which matter less once your team has decided to own the code path end to end.
Two more things matter for enrichment in an internal tool. First, profile unification across professional networks and social platforms requires a resolver step that runs before the waterfall, which is why most teams standardize on a single canonical identity key (the professional-network ID is the most common). Second, candidate profiles need a re-enrichment loop because profile data ages quickly, which is where the signal layer, covered next, pays the enrichment layer back.
Passive candidate monitoring and job-change detection
Silver medalists are the candidates you interviewed, liked, and did not hire. Six months later half of them have moved jobs. A third of those moves are into a role that would have fit your last requisition. Nobody on your team has a process for catching them, because the existing ATS treats candidates as records in a pipeline rather than people who exist in the world.
One boutique legal recruiting agency we spoke to framed it plainly, saying the sourcing move with the biggest payoff they make is watching for "partners who have recently changed jobs." Teams we spoke with in executive search and in-house TA described running similar watchlists around leadership movements and their own internal hiring pipelines.
Passive candidate monitoring runs on webhooks rather than stored searches you refresh on a schedule. You register watchers on the candidates already in your database (silver medalists, past applicants, referrals, hired-then-left alumni) and you receive signals when their status changes. A Watcher API endpoint that fires on job change, profile edits, or employer funding events is what makes this practical without a nightly scrape of any professional network.
A minimal webhook handler needs three guards:
HMAC verification. Every webhook body is signed with a shared secret. Verify the signature before you trust the payload, or you will get a bad weekend when someone discovers your public endpoint.
Idempotency. The same signal can fire twice during a retry. Deduplicate on a signal ID and a received-at timestamp before you write to your ATS.
Replay protection. Reject signals older than your chosen window (five minutes is common) to block replay attacks.
The handler itself is small:
@app.post("/webhook/candidate-signal") def receive_signal(request): body = request.body if not hmac_valid(body, request.headers["X-Signature"], SECRET): return 401 event = json.loads(body) if seen(event["id"]): return 200 store(event["id"]) route_to_recruiter(event) return 200
@app.post("/webhook/candidate-signal") def receive_signal(request): body = request.body if not hmac_valid(body, request.headers["X-Signature"], SECRET): return 401 event = json.loads(body) if seen(event["id"]): return 200 store(event["id"]) route_to_recruiter(event) return 200
@app.post("/webhook/candidate-signal") def receive_signal(request): body = request.body if not hmac_valid(body, request.headers["X-Signature"], SECRET): return 401 event = json.loads(body) if seen(event["id"]): return 200 store(event["id"]) route_to_recruiter(event) return 200
The payload itself carries the candidate ID, the signal type (job_change, funding_round, profile_edit, new_title), a timestamp, and enough context to route the alert. Routing is your call, whether that means a Slack message to the account owner, an ATS stage change, a sequencer kick, or a scoring nudge.
None of the public sourcing-tool demos we reviewed show this step, because it is less visually impressive than a search result. It is also where the stack earns its compounding return, since the handler replaces "we remembered to check" with "we were notified." Crustdata has a separate guide on how to track job changes for GTM, sales, and recruiting that walks through building job-change monitoring workflows for recruiters and using job-change webhooks in recruiting systems in more depth.
Precision talent search and filtering at scale
One specialist tech-recruiting agency we spoke to described an assignment that lives at the edge of every vendor tool, namely sourcing staff-level ML engineers who had shipped production ranking systems at a defined set of consumer-tech companies within a specific tenure window. Teams we spoke with in executive search hit the mirror image of the same problem, where the filter is a pattern of prior roles and company trajectories rather than a single skill. Both cases fail against dashboard UIs and only succeed once the filter can be composed as code.
Precision search is where a 60+ filter People API earns its keep. The filter combinations that matter for recruiting differ from the ones that matter for sales, and here are a few representative shapes we have seen across buyer transcripts.
Engineers who worked at a top-tier fintech between 2016 and 2020, now based in New York, open to senior IC roles.
Solutions engineers with experience at Series B to Series D SaaS companies, AWS certifications, two or more years in a customer-facing role, based in major US tech hubs.
Account executives who joined their current firm in the last 18 months (a classic silver-medalist reopen, most common in agency talent pools).
Data engineers across Europe and Asia with Spark, Airflow, and Snowflake experience, currently at Series B or later startups.
ML engineers who contributed to a specific set of open-source projects and work at companies below 500 employees.
Each of these is expressible as a JSON filter body against People Search. The filter logic supports AND, OR, NOT, and nested conditions, which is what lets you write exec-search longlists that would be impossible against the dashboard UIs of the major legacy-data vendors. A specialist tech-recruiting agency encodes its AI engineer mapping as a filter expression checked into its repo rather than rebuilding the list manually each time.
The pattern we see working is to define the filter as code, check it into your repo, and parameterize it per requisition. That way a recruiter tweaks inputs on a saved filter rather than rebuilding the search every time. This is a big unlock for agencies running the same search shape (senior backend, infrastructure, ML) across many clients. Further reading on finding engineers by alumni company and tenure window and building longlists for executive search with live people data covers the filter shapes in more depth.
ATS and workflow integration
This section is the one every public recruiting-tool demo skips. The webinars and walkthroughs of every major no-code automation platform, AI-agent builder, workflow runner, and sourcing tool we reviewed all stop at "candidate scored" and hand the last mile back to the recruiter as a CSV. The round-trip into the ATS is where most internal tools fail in month three, because writing candidates back into the system of record is harder than any of the upstream steps.
The round-trip starts with a trigger, whether a requisition opening, a signal firing, or a recruiter clicking "find more." A search call fires, the waterfall enriches the candidate, a scoring step runs, and the ATS write lands the candidate object plus enrichment fields in the system of record. Every downstream stage change or new signal triggers a second write back into the ATS. Done correctly, the ATS becomes the single place your recruiters work, and the external APIs become infrastructure they never see.
The biggest trap here is rate limits. Most staffing and recruiting ATSs publish a per-second or per-minute ceiling, and a freshly deployed sync job that ignores it can burn through the daily quota in a few minutes. Teams we spoke with describe the same class of problem from the data side, often summarized as "searching the ATS is a nightmare" when every CV arrives in a different schema, which becomes worse when your sync job re-writes the same malformed records in a loop.
Four patterns prevent this, and they apply to every mainstream staffing and recruiting ATS we have integrated against:
Use modified-timestamp cursors, not offset pagination. On some legacy staffing ATSs, offset-based /search results are not deterministic across requests; the totals can shift from 101,029 to 101,032 between two calls because the underlying index is being written to. Cursor on the last-modified timestamp, filter everything newer than your last successful sync, and you get a deterministic, restartable stream.
Read the rate-limit headers. Most modern ATSs expose a remaining-quota header on every response. Throttle your worker to stay above ten percent of the quota at all times.
Exponential backoff with jitter, not fixed retry. A hundred workers retrying after exactly 30 seconds will produce the same 429 wave that disabled the account the first time. Random jitter on top of exponential backoff spreads the load.
Idempotent writes keyed on your canonical ID. Every ATS write should carry an idempotency key (the professional-network ID, the email hash, whatever you chose as your canonical). That way a retry never creates a duplicate candidate record, and a half-failed batch does not produce a dirty ATS.
The webhook direction of the round-trip matters too. Most modern ATSs send webhooks on stage change, hire, reject, and note-added. Your handler reads those, re-enriches the candidate, and updates your scoring model. Verify the signature (HMAC-SHA256 is the most common scheme, but check your vendor's documentation), dedupe on the event ID, and store the raw event for replay. This is the plumbing behind pushing candidate enrichment into your ATS and keeping ATS records fresh with webhooks.
Evaluating and replacing vendor stacks
Most teams arrive at "build" after trying some combination of the major outbound-enrichment platforms, B2B data providers, scraped-dataset vendors, and legacy recruiter-database products. The real question is which pieces of your current stack you keep, which you replace with API calls, and what the hybrid looks like in production.
In practice, the decision comes down to four axes:
Freshness. How often is the underlying data refreshed, and is live enrichment an option? A quarterly-refreshed database works for account-level analytics but falls short for a job-change signal workflow. Look for vendors that expose a live-enrichment endpoint in addition to bulk drops.
Coverage. What is the realistic profile count for the verticals you hire in? Some vendors publish large headline numbers, but the real question is whether their coverage for your specific filter set (for example, nurse practitioners with FNP-BC in Arizona) is actually usable. Run a 100-candidate pilot against your own rubric before signing anything.
API design. Is there a documented REST API with real filter operators, or is it a dashboard with an API afterthought? Tools that were built dashboard-first tend to have API surfaces that cover the 20% of cases the product team remembered.
Where the ceiling is. At what usage level does the vendor's pricing stop making sense? Per-credit pricing works at a handful of accounts per week; it becomes expensive when you process tens of thousands per month. Seat-based models work for sales teams; they work poorly when you need five recruiters to share one pool of signals.
The hybrid pattern we see most often in our call base keeps the ATS, replaces the sourcing and signal tools with APIs, and replaces the enrichment dashboard with a waterfall in your own code. Crustdata fits the API-first side of that pattern with a live People Search endpoint, a People Enrichment endpoint, and webhook-based signal feeds through the Watcher API, plus bulk dataset delivery when your volume crosses the threshold where per-call pricing stops making sense. Teams making this decision often start by evaluating recruiting data freshness and coverage and comparing people data providers for staffing platforms before picking the API vendor.
Reference architecture: a complete sourcing system on APIs
The diagram below shows how a recruiter request flows through the whole system, from the recruiter clicking "find candidates" down to the ATS record being written.
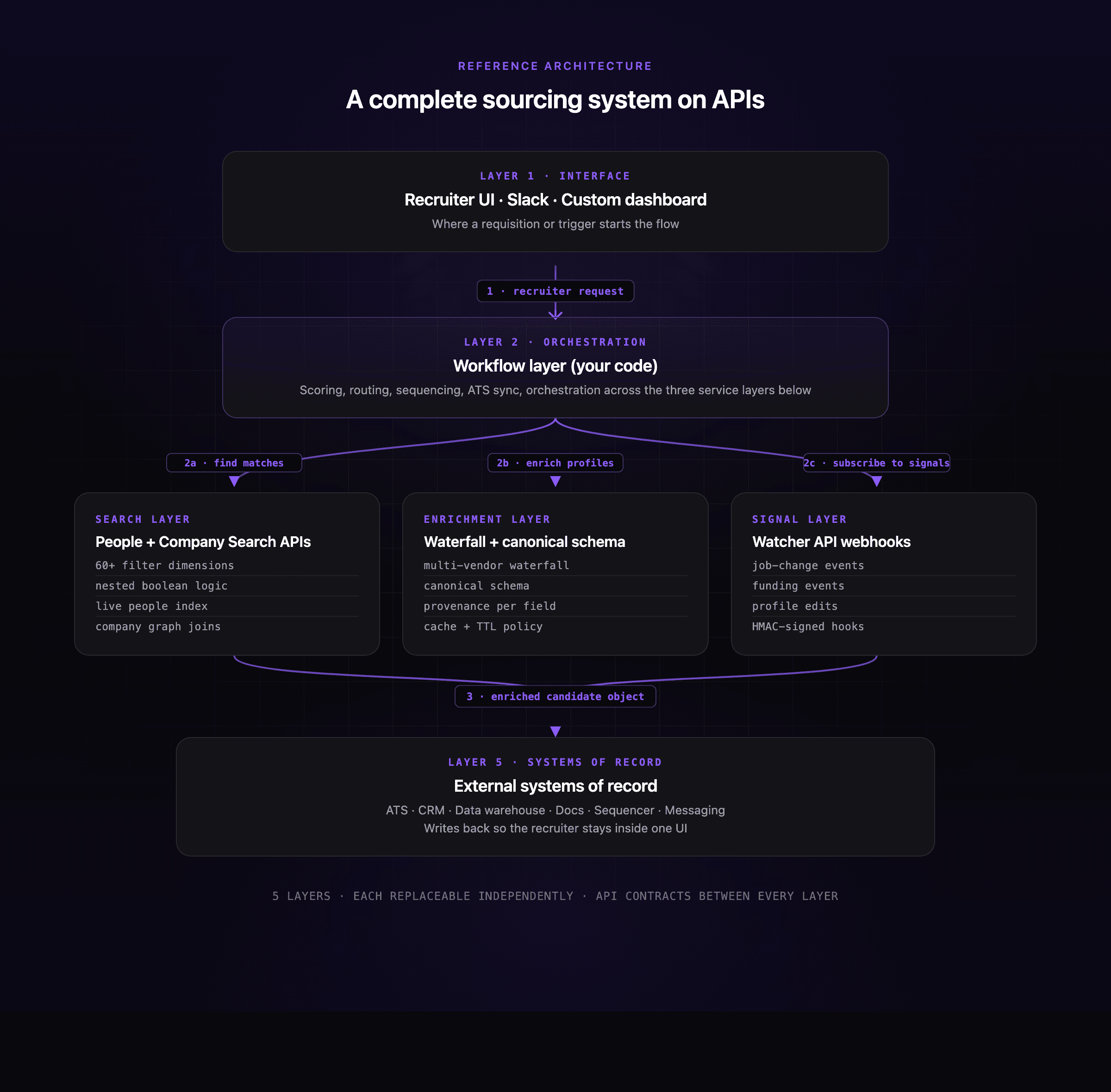
Reading the flow top-down: a recruiter opens a requisition or a signal fires (step 1). The workflow layer, which is your code, picks up the trigger and calls into the three service layers in whatever order the requisition needs: Search to find matches, Enrichment to fill in profile data, Signal to subscribe to future changes on those candidates (step 2a, 2b, 2c). The workflow layer assembles the enriched candidate object and writes it into the ATS and any other downstream systems (step 3). Every follow-up event, whether a stage change in the ATS or a job-change webhook from the signal layer, flows back into the workflow layer, which decides whether to re-enrich, re-score, or route a notification. The point of splitting it this way is that you can swap any one of the three service layers for a different vendor without rewriting the workflow code, because the contract between workflow and each service is a small, documented API surface.
For a 100,000-profile-per-year operation, at roughly $0.50 per live enrichment call, the annual enrichment spend lands around $50,000. Add search and signal volume and the all-in API cost stays well below what a comparable all-in platform (ATS plus CRM plus signal layer plus sourcing tool) would charge for equivalent capability. The economics flip somewhere between 50,000 and 200,000 profiles per year, depending on how much of your current spend sits in seat fees versus data fees.
The important thing to notice in this diagram is that no vendor owns the recruiter's whole day. The ATS holds the pipeline, the sourcing brain is yours, the signal feed is yours, and the enrichment canonical is yours. In practice, the builder's playbook keeps the ATS and wraps API calls around it with code you own, which is the same pattern teams take when they build a recruiting copilot using people search and enrichment.
Getting started: five concrete first steps
These are the five moves we have seen internal-builder teams ship first, in the order that compounds fastest.
1. Run a 50-candidate loop end to end. Pick one requisition. Run search, waterfall enrichment, store the profile in your canonical schema, and hand the shortlist to a recruiter. Measure cost per enriched profile and time from search to shortlist. The point is to get the full pipeline working on one real request before you scale it.
2. Test three signal types in a staging endpoint. Register watchers on job change, employer funding round, and profile edit. Run them against a list of 500 existing candidates in your database. Verify HMAC signatures, dedupe by event ID, and confirm your Slack routing works before you wire anything to production.
3. Map your ATS schema and sync 1,000 records. Pick your canonical ID (the professional-network ID is the most common). Write the adapter that maps your canonical profile into your ATS custom fields. Sync 1,000 records using a modified-timestamp cursor, and read the rate-limit header on every response. If your quota usage looks healthy, open it up to the full base.
4. Estimate production volume. Work out monthly API volume: new requisitions times candidates per req, plus signal events, plus re-enrichment on a rolling basis. Compare against your vendor's per-call pricing and their bulk-dataset threshold. Crustdata and most peers let you switch from per-call to bulk when volume warrants.
5. Shadow-run against your existing tool. Take two live requisitions, run them through both your new pipeline and your current sourcing tool, and compare coverage, freshness, and recruiter response rate. This is the single piece of evidence that gets a pilot expanded inside your org.
When pilot volume clears, the next question is usually when to switch from per-call enrichment to bulk dataset purchase.
Frequently asked questions
How do I sync candidates to my ATS without getting rate-limited out? Throttle your workers to stay above ten percent of the remaining-quota header at all times, use exponential backoff with random jitter on 429s, and run idempotent writes keyed on your canonical ID. Most staffing ATSs publish per-second or per-minute quotas, so the goal is to stay well below those ceilings across every worker in your pool.
Why are my ATS pagination totals changing between requests? On some ATSs, offset-based /search results are not deterministic across calls because the underlying index is being written to continuously. Switch to cursor pagination on the last-modified timestamp, filter on everything newer than your last sync's high-watermark, and you get a stream you can restart cleanly.
Can I point an AI recruiting agent at a modern ATS? Yes. Most modern ATSs expose REST APIs with documented candidate, application, and job endpoints, and send webhooks on stage changes and hires. Write your agent as a workflow-layer module that consumes the webhooks and calls back with write operations; do not let the agent hit the ATS without an idempotency key.
How do I move from a no-code spreadsheet enrichment tool to my own waterfall? Define one canonical profile schema in your database. Write an adapter per enrichment provider that returns fields in that schema. Order your providers by hit rate and cost, and iterate through them on each enrichment call until the profile is complete or the list is exhausted. The whole loop is about 80 lines of code.
How do I keep a silver-medalist list fresh without pounding a provider's API every night? Use a Watcher API or equivalent webhook feed to subscribe to job-change and profile-edit signals on your silver-medalist set. You pay per event received, not per nightly refresh call, which is both cheaper and closer to real-time.
How do I verify an ATS webhook actually came from the ATS vendor? Most modern ATSs sign each webhook body with an HMAC-SHA256 signature using a shared secret you configure when you register the webhook. Recompute the signature in your handler and compare it to the signature header; reject any request where they do not match. Dedupe on event ID to handle retries, and drop events older than five minutes to block replay.
Closing
Three things to take into your next planning session.
First, the build versus buy decision gets easier when you frame what you are actually building. The build keeps the ATS in place and wraps API calls around it with code you own, so the recruiter stays inside one UI while everything upstream of the ATS becomes yours to compose.
Second, search is the heart of the system because finding the right candidate for an open role is the whole point. Get search right first, since everything downstream depends on the list of candidates it returns. Once search is working cleanly, the signal layer is what compounds the investment over time, because it turns your silver-medalist pool and past applicants into a living watchlist instead of a static table that goes stale.
Third, Claude Code plus a small set of documented APIs has removed the engineering bottleneck that used to make "build" a five-engineer project. The teams we see shipping this well are two people deep, one product lead and one engineer, working against the same APIs any recruiting-tool vendor consumes.
When you are ready to run the 50-candidate loop from step one, Crustdata's People Search, People Enrichment, and Watcher APIs are what the architecture here is built on, with free credits for your first enrichments so your pilot costs nothing until you have the evidence you need. Crustdata is built for exactly this use case, with live APIs, webhooks, and bulk datasets that you compose into the recruiting tool your team has been told to wait for.



Products
Popular Use Cases
Competitor Comparisons
Use Cases
95 Third Street, 2nd Floor, San Francisco,
California 94103, United States of America
© 2026 Crustdata Inc.
Products
Popular Use Cases
Competitor Comparisons
Use Cases
95 Third Street, 2nd Floor, San Francisco,
California 94103, United States of America
© 2025 CrustData Inc.
Products
Popular Use Cases
Competitor Comparisons
Use Cases
95 Third Street, 2nd Floor, San Francisco,
California 94103, United States of America
© 2026 Crustdata Inc.