Candidate Enrichment Guide: Benefits & Best Practices
Explore everything you need to know about candidate enrichment to improve sourcing accuracy and engage the right candidates faster.
Published
Written by
Chris P.
Reviewed by
Nithish A.
Read time
7
minutes

Your ATS holds years of candidate relationships. The problem is that most of those records no longer reflect reality. According to the U.S. Bureau of Labor Statistics, the median number of years wage and salary workers had been with their current employer was 3.9 years in January 2024, the lowest since 2002.
That means the average candidate in your ATS has likely changed roles at least once since they last applied. This guide covers what candidate enrichment includes, how it works, and the best practices that make enrichment improve pipeline quality.
Key Takeaways
Candidate enrichment covers five data layers: contact data, employment history, skills, intent signals, and firmographic data about the candidate's current employer.
Batch enrichment cleans existing records on a defined cadence; real-time enrichment populates profiles at the point of creation; both serve different purposes, and neither replaces the other.
Enriching candidate records from external sources carries compliance obligations under GDPR and CCPA that most teams do not account for at implementation.
Intent signals tell you not just which candidates match a role, but which ones are most likely to respond to outreach right now.
What Is Candidate Enrichment?
Candidate enrichment is commonly described as adding contact details to an ATS record. That is the narrowest version of what it does. Full enrichment covers five data layers, each serving a different part of the recruiting workflow and each decaying at a different rate.
Before getting into those layers, one distinction worth making upfront: candidate enrichment is not the same as resume parsing.
Candidate Enrichment vs. Resume Parsing
Resume parsing extracts structured data from a document that the candidate submitted. Candidate enrichment pulls current data from external sources regardless of what the candidate shared or when. Parsing captures what a candidate chose to disclose at the time of application. Enrichment captures what is verifiably true about them right now.
A parsed resume reflects someone's self-reported history from months or years ago. An enriched profile reflects where they actually work today, what they actually do, and how to actually reach them.
The 5 Data Layers Candidate Enrichment Covers
Each layer fails differently and decays at a different rate. Here is what enrichment looks like across all five.
Contact data: Verified email addresses, direct phone numbers, and LinkedIn profile URLs. Real-time enrichment APIs update contact information as candidates change roles, rather than serving a stored snapshot from the last refresh cycle. This is the layer most teams prioritize and the one that decays fastest.
Employment history: Current employer, job title, tenure, and career progression. It is the most commonly outdated field in any ATS because candidates update their professional profiles far more often than they notify recruiters of changes. With a median job tenure of just 3.9 years, a candidate who applied two or three years ago has likely already moved on.
Skills and certifications: Structured skills tags inferred from job titles, work history, and public profile data. Skills inference tools parse job titles and experience into structured skill tags that make keyword-based ATS search significantly more accurate. Without this layer, the same search against the same database returns a fraction of the relevant candidates.
Intent signals: Tenure length, recent job platform activity, and job change detection. This layer separates passive candidate identification from passive candidate prioritization. It tells you not just who is qualified but who is likely to be receptive to a conversation right now. Knowing how to read these signals before candidates make their move public is what turns a passive sourcing strategy from volume-based to timing-based.
Firmographic data: Data about the candidate's current employer: company size, growth trajectory, funding status, and headcount trends. Most relevant for roles where industry domain or company-stage experience is part of the brief.
Here is how these layers compare across the two dimensions that matter most for sourcing:
Data Layer | What It Covers | Decay Rate |
Contact data | Email, phone, LinkedIn URL | High |
Employment history | Employer, title, tenure | High |
Skills and certifications | Structured tags from work history | Medium |
Intent signals | Tenure length, platform activity, job change flags | Continuous |
Firmographic data | Employer size, funding, headcount trends | Medium |
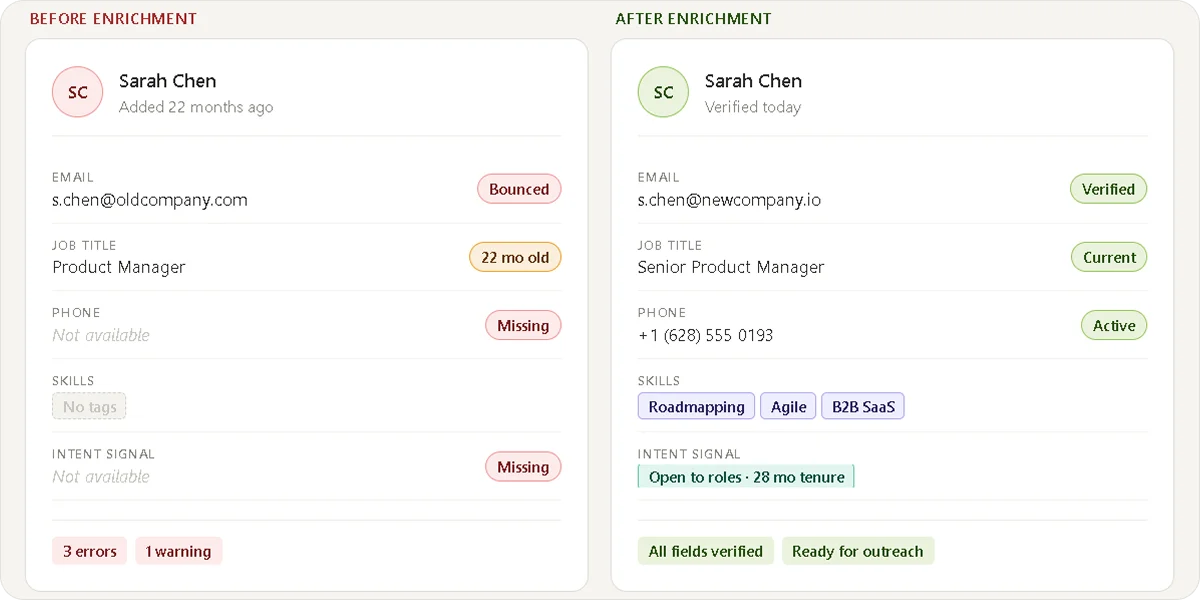
Benefits of Candidate Enrichment
The business case for enrichment is easy to make in general terms. The benefits below are specific and tied to the parts of the recruiting workflow where incomplete data creates the most friction.
Your Existing ATS Becomes a Live Sourcing Tool
Most ATS databases contain years of candidate relationships that go untapped because the records are too incomplete to surface in a search. The proportion of sourced hires rediscovered within a company's CRM or ATS rose from 29.1% in 2021 to 44% in 2024, according to Gem's 2025 Recruiting Benchmarks report. That shift did not happen because databases got bigger. It happened because enrichment made existing records searchable.
Outreach Response Rates Improve
Reaching a candidate at the right company, with the right title, through a verified channel removes the three most common reasons outreach fails before anyone reads it. When enrichment keeps contact data and employment history current, messages land where they are supposed to, which directly improves the rate at which candidates respond.
Organizations that use AI and enrichment tools most extensively consistently outperform those that do not across recruitment outcomes, candidate experience, and efficiency.
Recruiters Spend Time on Conversations, Not Research
A recruiter updating records manually can manage perhaps 50 to 100 profiles per day at reasonable quality. Automated enrichment removes that ceiling entirely. Recruiters receive complete, current profiles and move straight to evaluation and outreach rather than spending the first part of their day verifying whether the person still works where the ATS says they do.
Passive Candidate Outreach Gets Better Timing
Passive candidates are not a homogenous group. Some are quietly looking. Some are settled and will not respond regardless of how good the message is. Intent signals, specifically tenure analysis and job platform activity, identify which passive candidates are statistically more open to a conversation right now.
Without this layer, passive outreach is a volume exercise. With it, it becomes a timing strategy which consistently produces better conversion rates with fewer touches. Teams that have built repeatable sourcing systems around enriched data find that this timing layer is what separates one-off placements from consistent pipeline results.
Time-to-Fill Drops
Nearly half of all sourced hires now come from existing databases rather than new sourcing activity. An enriched internal database gets you to that pool faster, with verified contact data and structured skills for matching already in place. That combination shortens the sourcing stage without increasing spend, which is where most of the time-to-fill gains actually come from.
Compliance Considerations for Candidate Enrichment
This is the section most candidate enrichment content skips entirely. Enriching candidate records from external sources is not a neutral data operation. It carries compliance obligations under GDPR and CCPA that are separate from what applies to data candidates submit directly.
GDPR and Enrichment From External Sources
In the UK and EU, GDPR governs how candidate data is collected, used, and retained. Enriching a candidate record with data from external sources must be done on a lawful basis, and if the candidate has not been contacted in a defined period, many agencies default to a re-permission campaign before enriching and reactivating those records.
The most common lawful basis for enriching passive candidate records is legitimate interest under GDPR Article 6(1)(f). This requires documenting why you have a legitimate interest in holding and enriching that record, confirming that interest is not overridden by the candidate's right to privacy, and informing the candidate promptly after their record is enriched.
For records not contacted in over 12 months, a re-permission campaign before enrichment is the safer approach.
CCPA and US State Privacy Laws
In the US, data privacy regulations vary by state, with California's CCPA being the most stringent, but there is no federal equivalent to GDPR's broad consent framework. CCPA gives California residents the right to know what personal data is held about them, request deletion, and opt out of data sales.
For recruiting teams enriching records from third-party providers, this means maintaining a clear record of which data came from which source and being able to respond to data access and deletion requests that span enrichment layers.
Practical Compliance Steps Before You Enrich
Most compliance failures in enrichment programs happen not because teams ignored the rules but because they started enriching before defining how they would manage what came back. These steps close that gap:
Document your lawful basis for enrichment for each candidate segment before the first enrichment run
Set a maximum retention period for enriched records and automate deletion or re-permission at that threshold
Run a re-permission campaign on any records not contacted in the past 12 months before enriching and reactivating them
Confirm your enrichment provider can demonstrate how their data was sourced and whether it meets your jurisdiction's requirements
Audit enriched fields quarterly to confirm you are not holding data you no longer have a lawful basis to retain
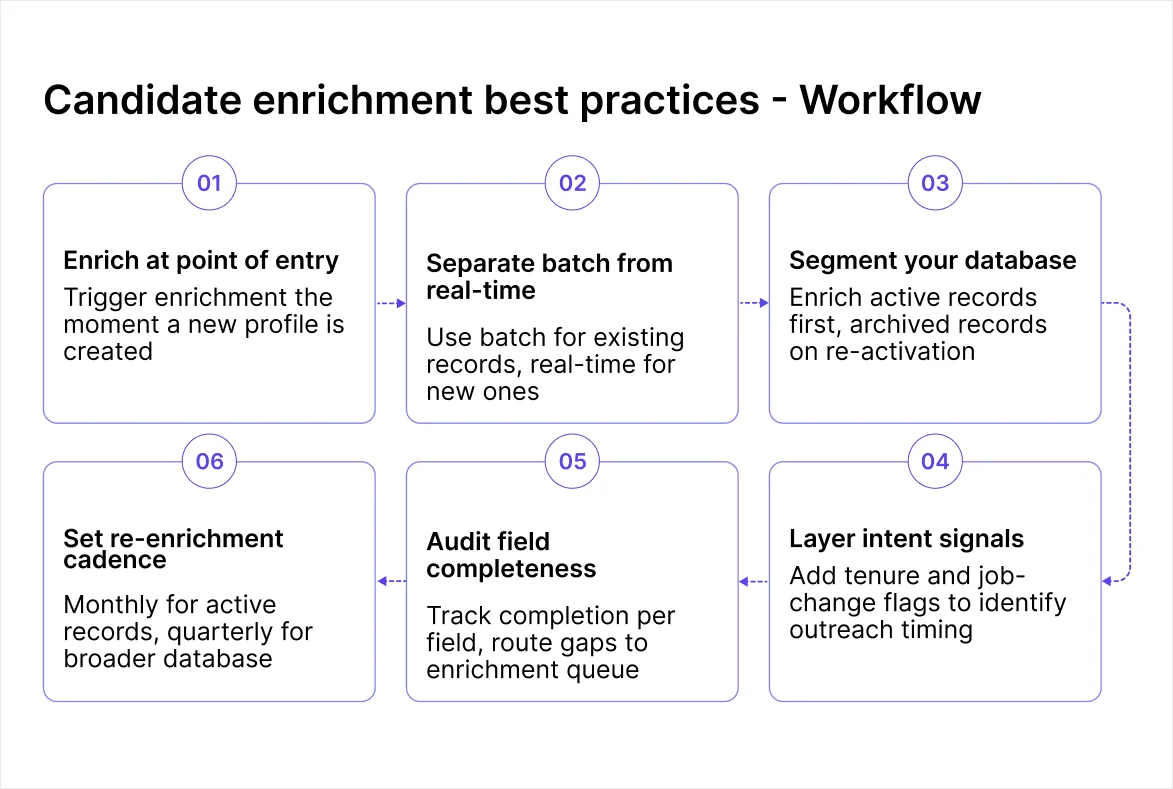
Candidate Enrichment Best Practices
Enrichment tools handle the data layer. The workflow around them determines whether that data actually improves pipeline quality or just fills fields that nobody uses downstream.
1. Enrich at the Point of Entry, Not as a Cleanup Exercise
The most common enrichment mistake is treating it as a periodic cleanup rather than an entry standard. By the time a batch cleanup runs, records have already been searched, rejected in keyword queries, and missed in pipeline reviews. Enriching every new profile at the moment it is created means your database is current from day one, not accurate only after the next batch cycle.
2. Separate Batch and Real-Time Enrichment by Purpose
Batch and real-time enrichment are not interchangeable. Batch enrichment processes an existing database in bulk, typically run as a one-time cleanup followed by scheduled refreshes. Real-time enrichment triggers on specific events, such as when a recruiter opens a candidate profile or when a new candidate is added, pulling the latest available data at that moment. Treating them as the same thing leaves gaps in both directions.
3. Segment Your Database Before Running Enrichment
Not all records deserve the same enrichment investment. Run enrichment in priority order rather than across the full database at once:
Active pipeline candidates and recent finalists first
Candidates who reached the final stage in the last 24 months
Broader active database third
Archived records only on reactivation
This keeps costs manageable while protecting the records that actually feed active sourcing. Teams doing high-volume candidate sourcing find segmentation especially important because running enrichment uniformly at scale burns budget on records that will never enter an active pipeline.
4. Layer Intent Signals Onto Enriched Contact Data
Contact data tells you where a candidate is. Intent signals tell you when to reach them. Tenure analysis identifies candidates statistically more open to a conversation. Job change signals flag candidates who have recently moved, often a moment when they are actively evaluating their next step. Layering these signals onto enriched profiles changes passive outreach from a volume exercise into a timing-based strategy.
Crustdata's People API surfaces live hiring signals from target companies alongside contact and employment data, giving recruiting teams a timing layer that most ATS enrichment tools do not cover natively. For teams building this into a candidate shortlisting workflow, the signal layer is often what closes the gap between a qualified candidate and one who actually responds.
5. Audit Field Completeness by Field, Not by Record
A record with 8 of 10 fields populated looks healthy in aggregate, but may be missing the two fields your search queries depend on most. Track completion rates per field across your active pool. Fields consistently below threshold need a targeted enrichment pass, not just inclusion in the next general batch run. The fields that matter most vary by role type:
Role Type | Most Critical Fields |
Technical roles | Skills tags, GitHub or portfolio links |
Executive search | Direct phone, current employer, tenure |
High-volume hiring | Verified email, location, availability signals |
Passive sourcing | Intent signals, tenure length, job change flags |
6. Set a Re-Enrichment Cadence by Segment
A candidate enriched 18 months ago and never refreshed is not an enriched record. It is an outdated one with more fields. Here’s a practical cadence by segment:
Segment | Re-Enrichment Cadence |
Active pipeline candidates | Monthly |
Recent finalists (last 24 months) | Monthly |
Broader active database | Quarterly |
Archived records | On re-activation only |
How to Build a Candidate Enrichment Workflow
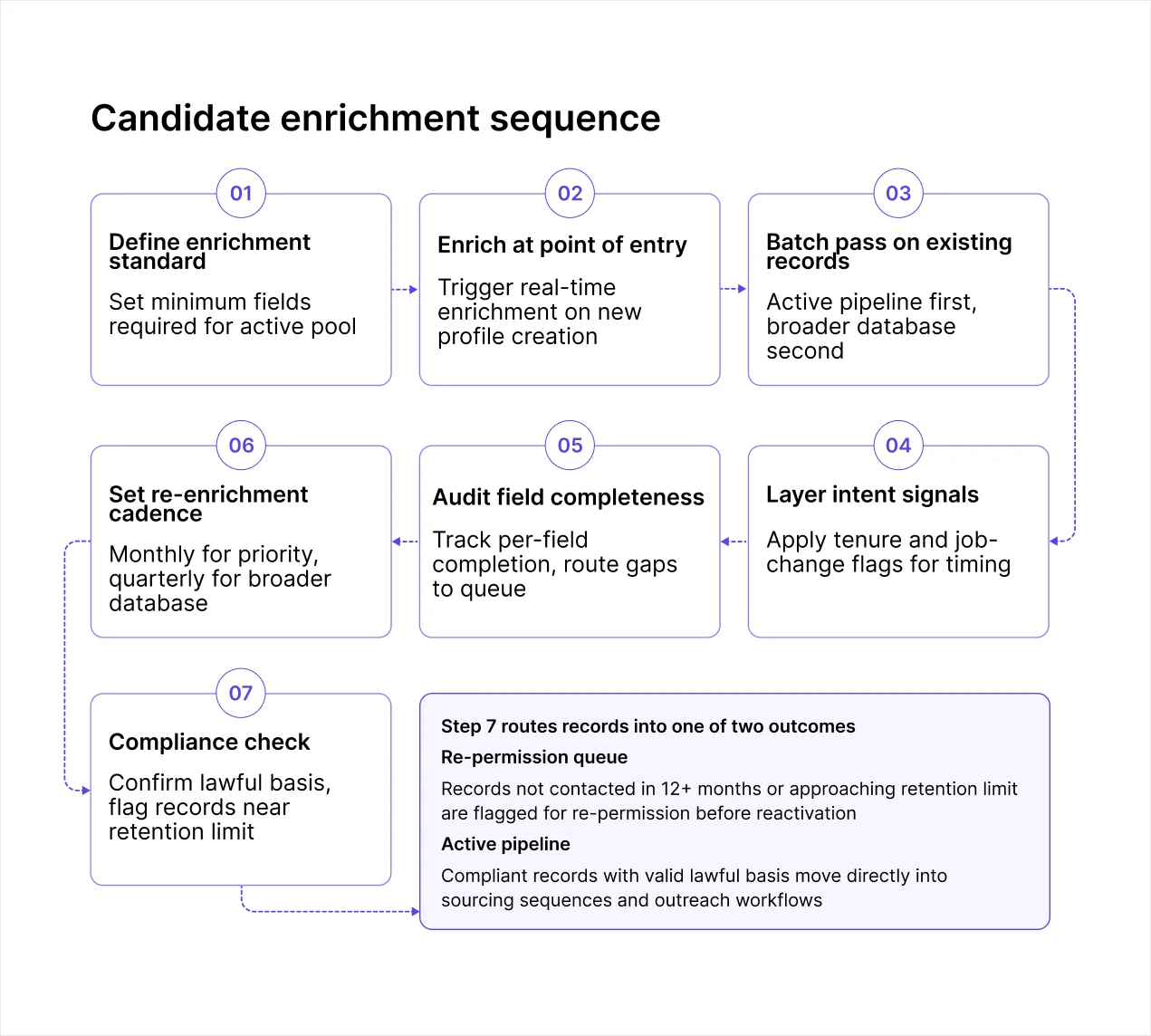
A candidate enrichment workflow is a sequence of decisions about when enrichment runs, which records it covers, and how enriched data connects to the rest of your recruiting stack. Here is the sequence that covers all of it without overlap:
Define your minimum enrichment standard: Identify which fields your search queries, scoring models, and outreach tools depend on. These become your floor for every record in the active pool
Enrich at point of entry: Trigger real-time enrichment the moment a new profile is created, before it enters any pipeline or queue
Run a priority batch pass on existing records: Active pipeline and recent finalists first, broader active database second
Layer intent signals: Apply tenure analysis and job change flags onto enriched profiles to identify outreach timing, not just candidate fit
Audit field completeness monthly: Track per-field completion rates and route below-threshold records to a targeted enrichment queue
Set re-enrichment cadence by segment: Monthly for active and high-priority records, quarterly for the broader database, and on reactivation for archived records
Run compliance checks in parallel: Confirm lawful basis for each enriched segment, flag records approaching retention limits, and automate re-permission campaigns before reactivating dormant records
How Crustdata Supports Candidate Enrichment Workflows
Most enrichment tools append contact and employment history from a stored database. That handles the baseline. It does not tell you what is happening at a candidate's current employer right now, whether the company is contracting, growing aggressively, or going through a leadership change, all of which affect how and when to reach that person.
Crustdata pulls from 10+ verified sources at the moment of each API request, returning current people and company data rather than a cached snapshot. For recruiting teams where enrichment feeds automated sourcing pipelines, the distinction between live data at request time and a monthly-refreshed database determines whether the outreach timing is right, not just whether the contact data is right.
Here’s what makes Crustdata particularly useful for candidate enrichment:
90+ people data points: Current employer, job title, employment history, and contact fields in a single profile pulled live at the point of request, covering the fields that decay fastest in any ATS
Real-time hiring signals: Headcount trends, job posting velocity, and executive movement at target companies give recruiting teams a timing layer on top of standard profile data
Watcher API with webhooks: Monitors a defined set of companies or people and fires a webhook the moment a qualifying event occurs, including a job change, promotion, or company growth spike, so outreach reaches candidates at the right moment rather than the next scheduled batch
60+ people filters: Precise searches by seniority, geography, past employers, skills, and tenure range, built for teams sourcing specific candidate profiles rather than browsing broad databases
Teams building structured candidate data pipelines can see what a candidate enrichment API should return and how Crustdata's people data fits alongside existing ATS and sourcing tools. For teams sourcing with minimal initial data, there is also a practical breakdown of how to identify strong candidates from that data, where enrichment quality makes the biggest difference.
Book a demo to see Crustdata's real-time people enrichment in action.
FAQ
How is candidate enrichment different from resume parsing?
Resume parsing extracts structured data from a document that the candidate submitted. Candidate enrichment pulls current data from external sources. Parsing captures what a candidate chose to share at the time of application. Enrichment captures what is verifiably current about them now.
How often should candidate records be re-enriched?
Active pipeline candidates and recent finalists monthly. The broader active database quarterly. Archived records only on reactivation.
Can candidate enrichment improve passive candidate outreach?
Yes, most effectively when paired with intent signals. Contact data and employment history tell you who is qualified. Tenure analysis and job change detection tell you who is likely receptive right now. The combination shifts passive sourcing from volume-based to timing-based, which produces better conversion with fewer touches.


Products
Popular Use Cases
Competitor Comparisons
Use Cases
95 Third Street, 2nd Floor, San Francisco,
California 94103, United States of America
© 2026 Crustdata Inc.
Products
Popular Use Cases
Competitor Comparisons
Use Cases
95 Third Street, 2nd Floor, San Francisco,
California 94103, United States of America
© 2025 CrustData Inc.
Products
Popular Use Cases
Competitor Comparisons
Use Cases
95 Third Street, 2nd Floor, San Francisco,
California 94103, United States of America
© 2026 Crustdata Inc.