6 Challenges in Lead Enrichment Accuracy [+ How to Fix Them]
Explore the challenges in lead enrichment accuracy to reduce bad data, improve targeting, and keep your sales workflows more reliable.
Published
Written by
Chris P.
Reviewed by
Nithish A.
Read time
7
minutes

Lead enrichment accuracy challenges are the specific points where enriched records return wrong, incomplete, or outdated data despite a working enrichment process. The problem is rarely the tool. Gartner estimates bad data costs organizations $12.9 million per year.
For most B2B teams, that cost shows up quietly: wasted outreach budget, reps working bad lists, and a pipeline that looks healthy but consistently underperforms at conversion. This guide covers 6 challenges in lead enrichment accuracy and the fix them.
Key Takeaways
Lead enrichment accuracy fails at predictable points: data decay, low match rates, single-source gaps, incomplete field coverage, and no re-enrichment cadence after the first pass.
A verified email on a wrong job title is still an inaccurate record; enrichment accuracy covers every field, not just deliverability.
Low match rates are usually caused by inconsistent or incomplete input records, not provider coverage gaps
Relying on one enrichment provider means inheriting its coverage gaps, refresh lag, and blind spots across your entire pipeline.
A one-time enrichment pass degrades at the same rate your candidates change jobs, move companies, and update their details, which is why enrichment has to run continuously.
What Drives Lead Enrichment Accuracy Challenges
Most teams assume enrichment accuracy is a provider problem. If the data comes back wrong, the tool must be at fault. That is rarely where the issue starts.
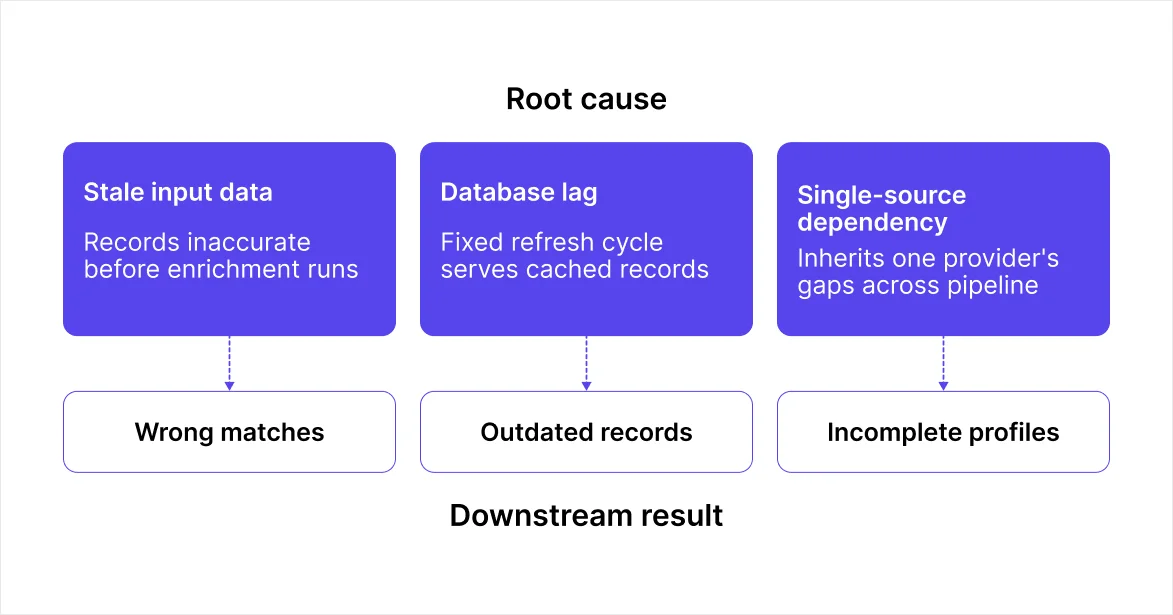
Accuracy breaks down at three points, each with a different cause and a different fix:
Stale input data: Enrichment works by matching your records against external sources. If those records are already inconsistent or incomplete before enrichment runs, the output reflects that. A misspelled domain or an unstandardized company name reduces match quality before the provider even starts.
Database lag: Most providers maintain a stored database refreshed on a fixed cycle. Every record they return reflects the last refresh, not the current state of that contact. For teams running automated workflows, that lag compounds across every record the pipeline touches.
Single-source dependency: No provider has complete coverage across every industry, geography, and company size. Relying on one source means inheriting all of its blind spots. You usually only find out when a sequence bounces or a rep dials a disconnected number.
The challenges shared below map each of these root causes to a specific failure point and a concrete fix.
6 Challenges in Lead Enrichment Accuracy To Look Out For and How to Fix Them
Lead enrichment accuracy breaks down in consistent, predictable ways. Most teams experience several of these at once without realizing they are separate problems with separate fixes. Here is each one and what to do about it.
1. Data Decay Between Enrichment and Execution
Most providers serve records from a stored database on a fixed refresh schedule. By the time an enriched record reaches your workflow, it may already reflect a role, employer, or contact detail that changed after the last update. For teams running automated sequences, that matters because the pipeline acts on those records without a human review step in between.
About 30% of B2B contact data becomes outdated each year due to job changes and company updates. That rate is not evenly distributed. Job titles and direct phone numbers decay faster than company domains or headquarters addresses. Your highest-priority contacts, senior decision-makers at fast-growing companies, tend to change roles more frequently than the rest of your database.
The fix:
Use a provider that queries live sources at the point of request rather than serving from a cached database. This removes the gap between when the data was collected and when it reaches your workflow
Set a re-enrichment cadence for existing records: quarterly at minimum, monthly for fast-moving sectors
Prioritize re-enrichment on your highest-value segments first, not your full database, to keep costs manageable while protecting the records that matter most
This is one of the most consistent B2B data quality problems teams encounter when auditing pipeline performance, and it is also one of the most fixable once the cadence is in place.
2. Low Match Rates From Incomplete Input Records
Low match rates get blamed on provider coverage. The actual cause is usually the input record itself.
An enrichment provider needs at least one reliable identifier to return a confident match: a company domain, verified email, or standardized company name. Incomplete fields, inconsistent company names, and URL encoding issues all lower match rates, and many leads never get enriched and move through your pipeline as thin, unqualified records.
Here is how match rate problems typically break down by input issue:
Input Problem | What It Causes | Fix |
Inconsistent company names | Duplicate or failed matches | Standardize against registry data before enrichment runs |
Missing company domain | No match returned | Resolve domain from company name before passing to enrichment |
Blank email field | Reduced confidence score | Flag for manual review before entering enrichment queue |
URL encoding errors | Failed API call | Validate and clean URLs in preprocessing step |
The fix is a standardization pass on input records before enrichment runs, not a provider switch. This is a pre-enrichment B2B data validation step that sits upstream of the tool itself.
3. Single-Source Dependency
No enrichment provider has complete coverage across every industry, geography, and company size. When you rely on one source, you inherit all of its blind spots without knowing where they are. Platforms that evaluate multiple sources in parallel rather than sequentially are more likely to return accurate, up-to-date data instead of simply the first available match.
The blind spots tend to cluster in predictable places:
Geography: Providers strong in North America often have thinner coverage for EMEA and APAC
Company size: Mid-market and SMB coverage is weaker than enterprise across most providers
Industry: Niche or emerging industries have less web presence to crawl, which reduces data density
Contact seniority: C-suite and VP-level contacts change roles more frequently, making them harder to keep current in any static database
The fix: Cross-reference high-priority accounts against a second independent source before records enter any active sequence. For teams enriching at scale, Crustdata queries 10+ independent sources per API call, which surfaces discrepancies at the enrichment stage rather than after a record has already been routed and acted on. You can see how that fits into a broader B2B data enrichment workflow.
4. Field Coverage Gaps
A record that returns a verified email but leaves job title, headcount, and technology stack blank is not an accurate record for scoring or routing purposes. It passed enrichment but it did not pass the standard your pipeline actually needs.
Field coverage gaps cause downstream problems that are easy to misdiagnose:
Scoring models assign arbitrary weights to incomplete profiles and produce unreliable rankings
Routing rules break when required fields are blank, sending records to the wrong queue or no queue at all
Personalization fails when outreach tools cannot pull the fields that the sequence template depends on
The fix: Audit field completeness by field, not by record. A record with 8 of 10 fields populated looks healthy in aggregate, but may be missing the two fields your scoring model weighs most heavily. Set a minimum threshold per field before records enter an active sequence, and route anything below the threshold to an enrichment queue rather than straight into outreach. Track which fields are consistently incomplete to identify whether the gap is a provider coverage issue or an input problem.
5. Treating Enrichment as a One-Time Project
Lead enrichment is an ongoing CRM hygiene workflow, not a one-time append process. Teams that enrich at implementation and consider the database current are operating on records that decay from the moment enrichment completes. By the second quarter, a meaningful share of those records already reflect roles, employers, and contact details that have changed.
The pattern looks like this:
When Enrichment Ran | Estimated Accuracy After |
At implementation | ~100% |
3 months later | ~92% |
6 months later | ~85% |
12 months later | ~70% |
These are directional figures based on a 30% annual decay rate. The actual drop depends on your industry and ICP seniority level.
The fix: Build enrichment triggers into your workflow at three points:
Point of entry: Enrich every new record the moment it enters your system, before it touches any scoring or routing logic
Scheduled re-enrichment: Run a full re-enrichment pass on existing records quarterly, or monthly for high-velocity sectors
Event-based triggers: Flag records for immediate re-enrichment when a qualifying change occurs at the account level, without waiting for the next scheduled batch
Crustdata's Watcher API handles the third trigger automatically. It monitors a defined account set and fires a webhook the moment an executive hire, headcount shift, or funding event occurs, so your records reflect changes as they happen rather than at the next refresh cycle. You can see how event-based monitoring fits into a broader automated lead enrichment pipeline.
6. No Feedback Loop Between Enrichment and Sales
Enrichment accuracy does not improve on its own. Without a structured feedback loop, accuracy problems stay invisible until they surface as bounce rates or missed quota. Those reps know which fields are wrong. Most teams have no mechanism to route that signal back into the enrichment process. The result is that the same inaccuracies surface repeatedly, absorbed as friction by individual reps rather than fixed at the source.
The result is a one-way system: enrichment appends data, sales uses it, inaccuracies get absorbed as friction, and nothing feeds back to improve the next enrichment run.
The fix:
Add a lightweight field-level flag in your CRM that lets reps mark specific fields as inaccurate without disrupting their workflow
Track flags by field type and provider to distinguish systematic accuracy gaps from one-off errors
Use flagged data to adjust enrichment rules, field thresholds, and provider weighting on a quarterly basis
Connect patterns back to your B2B data challenges audit so they surface at the process level rather than in individual rep complaints
How Crustdata Solves Lead Enrichment Accuracy at the Source
Every challenge in this article traces back to the same structural problem: enrichment that runs against data that is already aging. Validation patches help. Re-enrichment cadences help. But neither fixes the root cause, which is a provider serving records from a database that was accurate when it was built and less accurate every day since.
Crustdata is built differently. Instead of maintaining a stored database and refreshing it on a schedule, every API call triggers a live pull across 10+ verified sources at the moment of request. The record your pipeline receives reflects where that contact and company actually are right now, not where they were at the last refresh cycle.
That distinction matters most for the specific challenges covered in this article:
Data decay: Crustdata pulls live at the point of request, so the lag between enrichment and execution is removed. There is no gap for records to go wrong before they reach your workflow.
Single-source dependency: Pulling from 10+ independent sources per call means discrepancies surface at enrichment rather than after a record has been routed, scored, and acted on.
Field coverage gaps: A single API call returns 250+ company data points and 90+ people data points, covering firmographics, headcount trends, funding history, technology stack, and web traffic in one profile.
One-time enrichment problem: The Watcher API monitors a defined account set and fires a webhook the moment a qualifying change occurs, including executive hires, headcount shifts, and funding events, so your database updates in real time rather than at the next scheduled batch
Low match rates: 95+ company filters and 60+ people filters with nested boolean logic mean you can build precise queries that return high-confidence matches rather than broad pulls that inflate volume at the cost of accuracy.
For teams where enrichment feeds AI sales agent workflows or automated pipelines, these are not marginal improvements. An AI agent acting on a bad record does not just waste one touch. It executes every downstream step of that workflow on a wrong assumption, and the cost compounds with each one.
If lead enrichment accuracy is costing your team's pipeline, the fix starts at the data layer.
Book a demo to see Crustdata's real-time enrichment in action.
FAQ
What is lead enrichment accuracy?
Lead enrichment accuracy is how closely enriched fields in a record reflect the current real-world state of that contact or company. A record with a verified email, but a job title that changed six months ago has passed enrichment and failed accuracy.
What causes low match rates in lead enrichment?
Usually, the input record, not the provider. Missing company domains, inconsistent company name formatting, and blank identifier fields all reduce match rates before enrichment logic runs. Fix the input first before attributing the problem to coverage.
How often should enriched records be refreshed?
New records at the point of entry, existing records quarterly at a minimum. For high-velocity sectors like SaaS and tech, monthly is more appropriate. Event-based monitoring removes the dependency on scheduled cadences entirely by triggering re-enrichment the moment a qualifying change occurs at a target account.
Does using multiple enrichment sources actually improve accuracy?
Yes, and meaningfully so. Single-source enrichment inherits that provider's coverage gaps and refresh timing across your entire pipeline. Pulling from multiple independent sources per call surfaces discrepancies at enrichment rather than after records have already entered your workflow.
Can enrichment accuracy be improved without switching providers?
Often yes. Standardizing input records, auditing field completeness by field rather than by record, building a sales feedback loop into your CRM, and setting a re-enrichment cadence all improve accuracy without changing the underlying provider. The challenges in this article are mostly process failures, not tool failures.



Products
Popular Use Cases
Competitor Comparisons
Use Cases
95 Third Street, 2nd Floor, San Francisco,
California 94103, United States of America
© 2026 Crustdata Inc.
Products
Popular Use Cases
Competitor Comparisons
Use Cases
95 Third Street, 2nd Floor, San Francisco,
California 94103, United States of America
© 2025 CrustData Inc.
Products
Popular Use Cases
Competitor Comparisons
Use Cases
95 Third Street, 2nd Floor, San Francisco,
California 94103, United States of America
© 2026 Crustdata Inc.